
Rozhodovačka
Metody umělé inteligence
Váš denní počet odpovědí je omezen. Pro navýšení limitu či přístup do svého účtu s licencí se přihlaste.
Přihlásit seQR kód
Kód / krátká adresa
Zkopírujte kliknutím.
Nastavení cvičení
Pozor, nastavení je platné pouze pro toto cvičení a předmět.
Princip strojového učení
Umělá inteligence často využívá učení z dat, tzv. strojové učení. Vstupem strojového učení je velké množství dat (dataset), výstupem je naučený model pro řešení požadovaného úkolu. Máme-li dostatek dat popisujících vzhled a chování příšerek, můžeme naučit model, který bude pro nové příšerky odhadovat, zda jsou hodné, na základě jejich vzhledu.
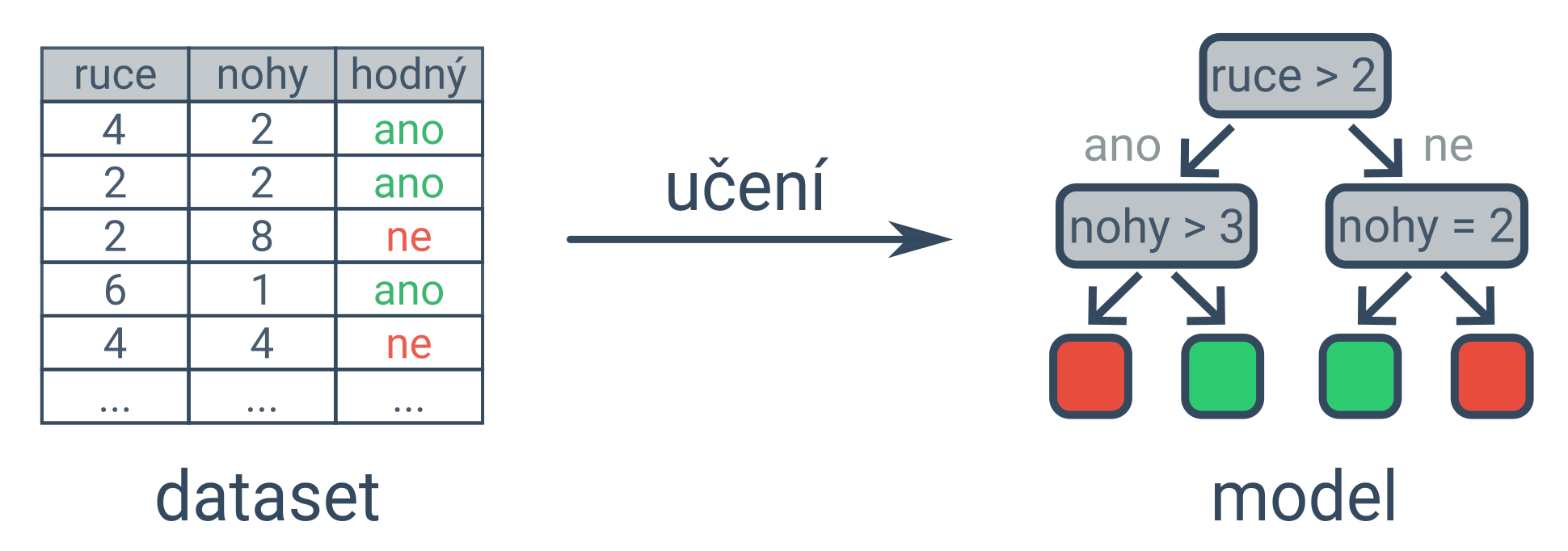
Klíčovou ingrediencí pro strojové učení je velké množství dat. Jednotlivé příklady jsou typicky poměrně jednoduché (např. jedna fotka), ale je jich hodně (někdy i miliony). Aby byl model užitečný, nestačí, aby si zapamatoval trénovací data (memorizace), musí být schopen určovat správný výstup i pro příklady nové (zobecňování, generalizace).
Příkladem modelu je rozhodovací strom (na obrázku výše) nebo neuronová síť (model volně inspirovaný sítí neuronů v mozku). Strojové učení může v závislosti na množství dat trvat vteřiny i celé dny, pro urychlení se proto někdy využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit).
Strojové učení lze vnímat jako alternativu ke klasickému programování, při kterém programátor zapisuje posloupnost přesných instrukcí (např. if-then pravidla nebo heuristika na základě zkušenosti). Strojové učení bude vhodným přístupem zejména tehdy, když není jasné, jak by takový klasický program měl vypadat a přitom lze sehnat rozsáhlé množství příkladů (např. detekce spamu). Strojové učení spíše nebude vhodným přístupem pro kritická rozhodnutí, kde není tolerovatelná žádná chyba a potřebujeme vysokou předvídatelnost a transparentnost chování (např. bankovní převod).
Aplikace strojového učení (příklady)
- detekce spamu
- diagnóza nemoci
- rozpoznání hlasu
- překlad textů
- doporučování filmů
- řízení auta
- generování obrázků podle popisu
Princip strojového učení (střední)
Vyřešeno:
