







Skvěle, štít %% dosažen
Pravděpodobnost ve strojovém učení
Rozhodovačka
QR kód
Kód / krátká adresa
Zkopírujte kliknutím.
Nastavení cvičení
Pozor, nastavení je platné pouze pro toto cvičení a předmět.
Pravděpodobnost ve strojovém učení
Pravděpodobnost umožňuje pracovat s nejistotou, která je ve strojovém učení nevyhnutelná, neboť model musí odhadovat odpovědi i pro nové příklady, které nikdy předtím neviděl.
Základy pravděpodobnosti
Pravděpodobnost P(A) je číslo mezi 0 a 1 vyjadřující míru jistoty či očekávání, že se jev A stal nebo stane. Pokud ze 200 e-mailů 10 obsahuje slovo „zázračný“, pak je pravděpodobnost výskytu slova „zázračný“ P(„zázračný“) = 0,05 = 5 %. Pravděpodobnost opačného jevu \neg A je doplněk do jedničky, tj. P(\neg A) = 1-P(A). Pravděpodobnost, že e-mail neobsahuje slovo „zázračný“, je 0,95.
Podmíněná pravděpodobnost P(A \mid B) je pravděpodobnost jevu A za předpokladu, že nastal jev B. Podmíněnou pravděpodobnost spočítáme jako P(A \mid B) = P(A \cap B) / P(B), kde P(A \cap B) je pravděpodobnost současného výskytu obou jevů. Pokud mezi 200 e-maily bylo 20 spamů a z nich 8 obsahovalo slovo „výhra“, tak podmíněná pravděpodobnost, že e-mail obsahuje slovo „zázračný“, pokud je spam, je P(„zázračný“ | spam) = P(„zázračný“ ∩ spam) / P(spam) = 8 / 20 = 0,04 = 40 %.
Pokud jev B nijak neovlivňuje pravděpodobnost jevu A, tj. P(A \mid B) = P(A), pak označujeme jevy A, B jako nezávislé. Například hody mincí jsou nezávislé. Naopak výskyt slova „zázračný“ není nezávislý na tom, zda jde o spam. Pravděpodobnost současného výskytu nezávislých jevů je rovna součinu jednotlivých pravděpodobností, tedy P(A \cap B) = P(A) \cdot P(B). (Obecně pro libovolné jevy platí P(A \cap B) = P(A) \cdot P(B \mid A) = P(B) \cdot P(A \mid B).)
Výpočty s pravděpodobností jsou zařazeny pod předmětem matematika.
Bayesova věta
Často umíme snadno určit P(B \mid A), kde A způsobuje nebo ovlivňuje B, ale zajímá nás opačná podmíněná pravděpodobnost P(A \mid B). Z posbíraných dat umíme snadno vypočítat pravděpodobnost, že e-mail obsahuje slovo „zázračný“, pokud jde o spam, ale pro klasifikaci e-mailů potřebujeme znát opačnou podmíněnou pravděpodobnost – pravděpodobnost, že jde o spam, když text obsahuje slovo „zázračný“. V takových případech lze podmíněnou pravděpodobnost „otočit“ podle Bayesovy věty:
P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)}
Odvození Bayesovy věty
Pravděpodobnost, že nastane A i B, můžeme vyjádřit pomocí dvou různých podmíněných pravděpodobností (z definice podmíněné pravděpodobnosti):
P(A \cap B) = P(A \mid B) \cdot P(B)
P(A \cap B) = P(B \mid A) \cdot P(A)
Porovnáním pravých stran dostaneme:
P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A)
Podělením obou stran P(B) již získáme Bayesovu větu:
P(A \mid B) = P(B \mid A) \cdot P(A) \mathbin{/} P(B)
Vzorec lze také vnímat jako update původní (nepodmíněné) pravděpodobnosti P(A) (prior) s přihlédnutím k nové informaci, že nastal jev B. Zpřesněná (podmíněná) pravděpodobnost P(A \mid B) se pak označuje jako posterior.
Příklad použití Bayesovy věty
Chceme určit pravděpodobnost, že má pacient rakovinu, pokud má pozitivní test. Prevalence rakoviny v testované populaci je 1 %. Pokud má pacient rakovinu, pak je test pozitivní v 90 %, pokud pacient rakovinu nemá, pak je test pozitivní ve 20 %.
Označme si T = pozitivní test, R = rakovina. Ze zadání víme: P(R) = 0{,}01, P(T \mid R) = 0{,}9, P(T \mid \neg R) = 0{,}2.
K použití Bayesovy věty potřebujeme spočítat celkovou pravděpodobnost pozitivního testu:
P(T) = P(R) \cdot P(T \mid R) + P(\neg R) \cdot P(T \mid \neg R)
Podle Bayesovy věty:
P(R \mid T) = P(R) \cdot P(T \mid R) / P(T) = 0{,}01 \cdot 0,9 / (0{,}01 \cdot 0{,}9 + 0{,}99 \cdot 0{,}2) = 0{,}009 / (0{,}009 + 0{,}198) = 0{,}009 / 0{,}207 = 0{,}043 = 4{,}3 \%
Pravděpodobnost rakoviny je tedy v této situaci i při pozitivním testu pouze 4,3 %. To se může zdát málo, ale je to dáno tím, že test je nezřídka pozitivní i pro pacienty bez rakoviny a těch je přitom v populaci výrazně více.
Pravděpodobnostní klasifikátor
Pravděpodobnostní modely lze nejsnáze využít pro řešení klasifikačních úloh (např. rozhodnout, zda je daný e-mail spam). Označme X příklad, který chceme klasifikovat, X_1, X_2, \ldots, X_n jeho jednotlivé atributy (např. přítomnost různých slov v textu e-mailu) a Y možné kategorie (spam / normální e-mail). Chceme predikovat kategorii s větší podmíněnou pravděpodobností P(Y \mid X). Tyto pravděpodobnosti můžeme spočítat s využitím Bayesovy věty:
P(Y \mid X) = P(X \mid Y) \cdot P(Y) \mathbin{/} P(X)
Zatímco určení P(Y) je snadné (spočítáme, jaký podíl e-mailů v trénovacích datech je spam), určení P(X \mid Y) vyžaduje exponenciálně mnoho příkladů vzhledem k počtu atributů (potřebovali bychom e-maily se všemi možnými kombinacemi uvažovaných slov). Možným řešením je pravděpodobnostní rozdělení odhadovat pouze přibližně pomocí nějakého modelu, který nemá exponenciální počet parametrů (např. neuronová síť).
Naivní Bayesův klasifikátor
Pro mnohé jednoduché problémy však stačí výrazně jednodušší řešení: předpokládat, že jednotlivé atributy jsou na sobě podmíněně nezávislé (při znalosti kategorie). Pak nám totiž stačí n jednoparametrických podmíněných pravděpodobností:
P(Y \mid X) = P(Y) \cdot P(X_1 \mid Y) \cdot P(X_2 \mid Y) \cdot \ldots \cdot P(X_n \mid Y) \mathbin{/} P(X)
Tento model se označuje jako Naivní Bayesův klasifikátor. Slovo „naivní“ se odkazuje právě na předpoklad podmíněné nezávislosti atributů, který typicky neplatí (např. přítomnost slova „zázračný“ zvyšuje pravděpodobnosti slova „lék“ i pokud víme, že jde o spam). Odhadnuté pravděpodobnosti tak mohou být hodně nepřesné. Pro úspěšnou klasifikaci však není podstatné, zda jsou pravděpodobnosti odhadnuté přesně, ale zda má skutečná kategorie nejvyšší odhadnutou pravděpodobnost, což často platí. Výhodou je nízký počet parametrů (lineární vzhledem k počtu atributů), nízký počet příkladů potřebných k učení a také rychlé učení (přímočarý výpočet hodnot parametrů).
Bayesovské sítě
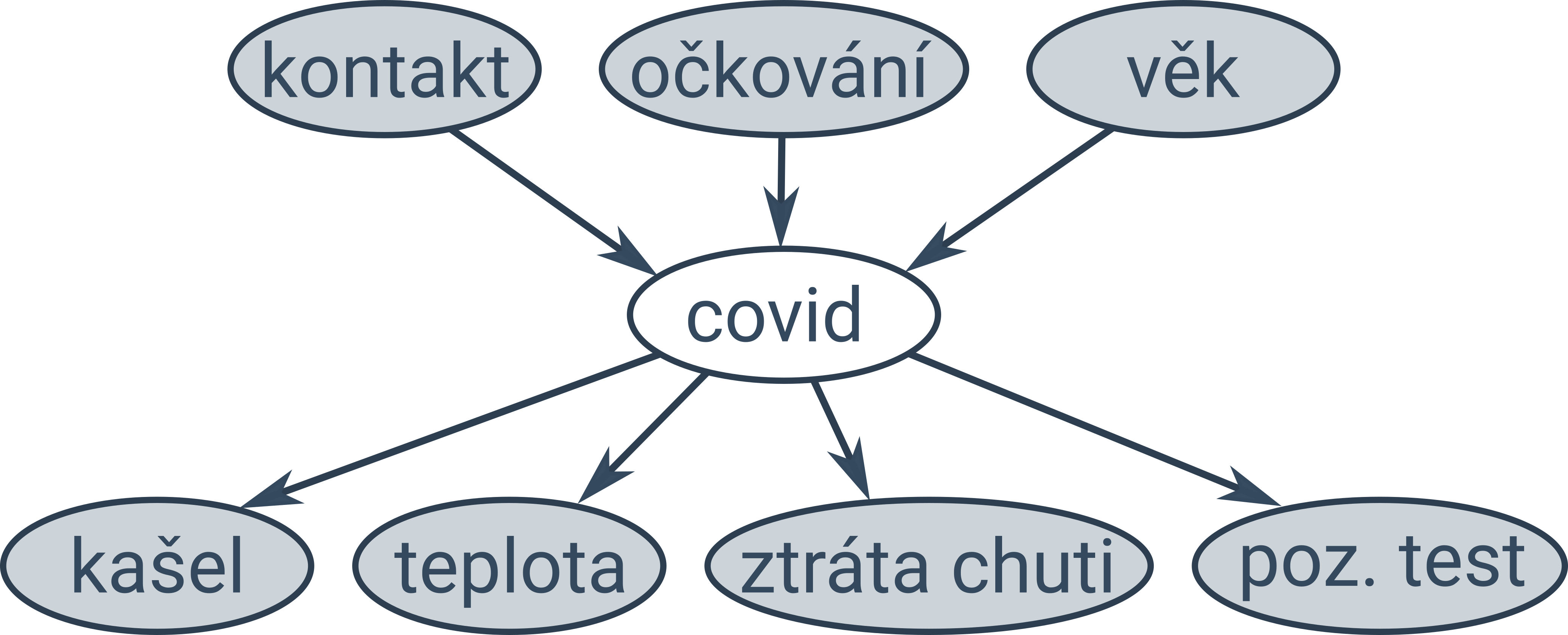
Naivní Bayesův klasifikátor předpokládá, že jsou všechny atributy podmíněně nezávislé. V některých případech víme, že některé atributy nezávislé jsou a jiné nejsou. Takovou situaci můžeme modelovat pomocí Bayesovských sítí, což je orientovaný graf zachycující vztahy mezi pozorovanými a skrytými proměnnými (pozorované proměnné jsou na obrázcích níže podbarvené šedě):
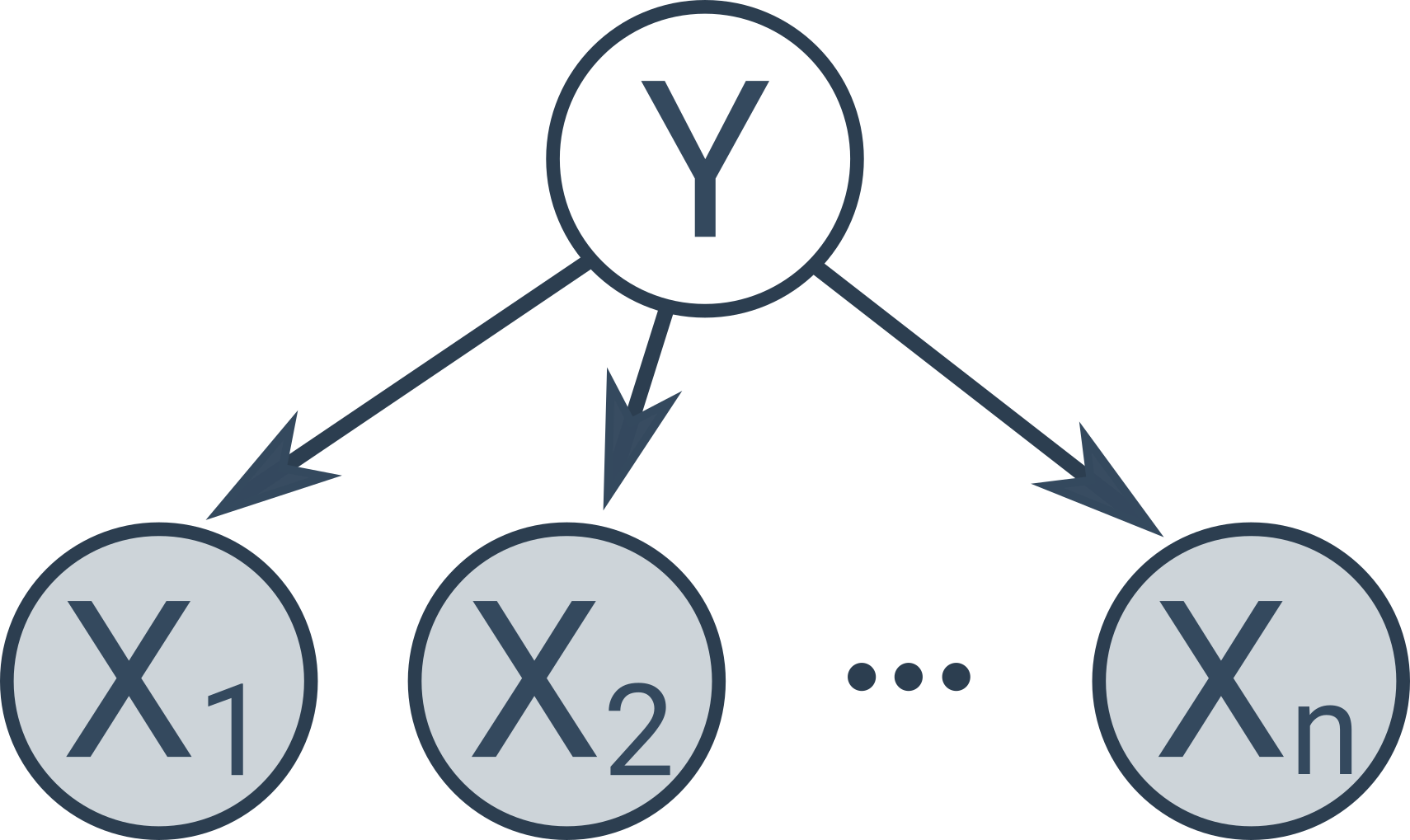
Naivní Bayesův klasifikátor je speciální typ Bayesovské sítě s následující jednoduchou strukturou:
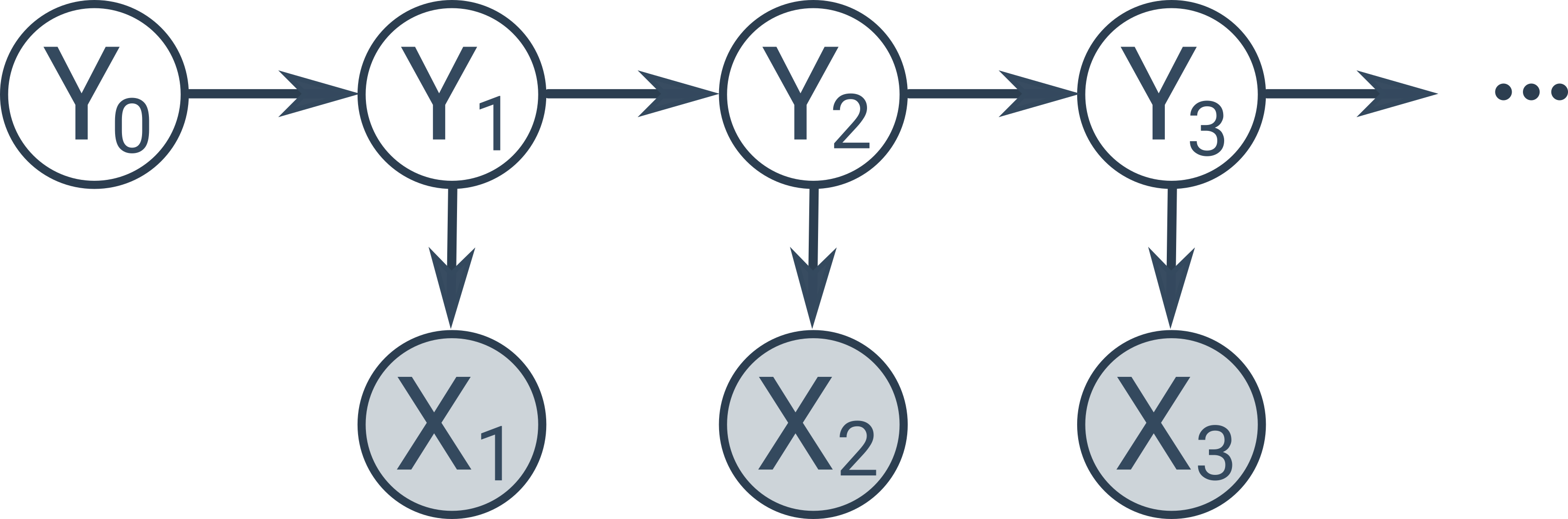
Existují další speciální typy Bayesovských sítí, např. skryté Markovovy modely, znázorňující časovou posloupnost skrytých stavů (poloha robota, vyslovovaný text), v níž každý stav závisí pouze na jednom předchozím stavu a produkuje pozorovatelné měření (měření ultrazvukového senzoru, zaznamenaný zvuk).
Pravděpodobnost ve strojovém učení (střední)
