







Skvěle, štít %% dosažen
Postup strojového učení
Rozhodovačka
QR kód
Kód / krátká adresa
Zkopírujte kliknutím.
Nastavení cvičení
Pozor, nastavení je platné pouze pro toto cvičení a předmět.
Postup strojového učení
Využití strojového učení zahrnuje následující fáze:
příprava datasetu – může zahrnovat sběr a anotování dat (doplnění požadovaného výstupu)
trénování modelu – určení vhodných hodnot parametrů modelu
testování modelu – na nových datech, která model neviděl během trénování
nasazení modelu – tedy jeho použití pro zadaný úkol
Typy přístupů
Přístupy ke strojovému učení lze rozlišit podle povahy signálu o požadovaném výstupu modelu:
učení s učitelem (angl. supervised learning) – požadovaný výstup je součástí trénovacích dat (např. zda je příšerka hodná, zda je e-mail spam). Doplňování požadovaných výstupů se říká anotování dat. Datům s požadovaným výstupem se pak někdy říká označkovaná data.
učení bez učitele (angl. unsupervised learning) – trénovací data neobsahují požadovaný výstup, úkolem je najít vzory v datech (např. podobné příšerky, podobné zprávy)
posilované učení (někdy též zpětnovazební učení, angl. reinforcement learning) = učení skrze interakci s prostředím zahrnující zpětnou vazbu na provedené akce (např. výhra v šachu, řízení auta bez nehod)
Různé přístupy jsou vhodné na různé typy úloh. Učením s učitelem se typicky řeší regrese, klasifikace, řazení a generování, učením bez učitele shlukování a hledání anomálií, posilovaným učením řízení. Často se však přístupy kombinují.
Modely
Pro řešení úloh strojového učení existuje celá řada modelů. Příkladem jsou lineární modely, rozhodovací stromy a neuronové sítě:
Lineární modely určují výstup na základě váženého součtu atributů. Pokud je 2 × počet rukou + 3 × počet nohou menší než 18, pak je příšerka hodná.
Rozhodovací stromy určují výstup na základě podmínek. Pokud má příšerka (více jak dvě ruce a nejvýše tři nohy) nebo (nejvýše dvě ruce a právě dvě nohy), pak je hodná.
Neuronové sítě se skládají z mnoha propojených neuronů, kde každý neuron počítá relativně jednoduchou funkci (podobně jako lineární model). Protože je ale neuronů hodně, je výsledná funkce určená neuronovou sítí složitá. Neurony jsou typicky uspořádané do několika vrstev. Učení neuronové sítě s mnoha vrstvami se označuje jako hluboké učení (angl. deep learning).
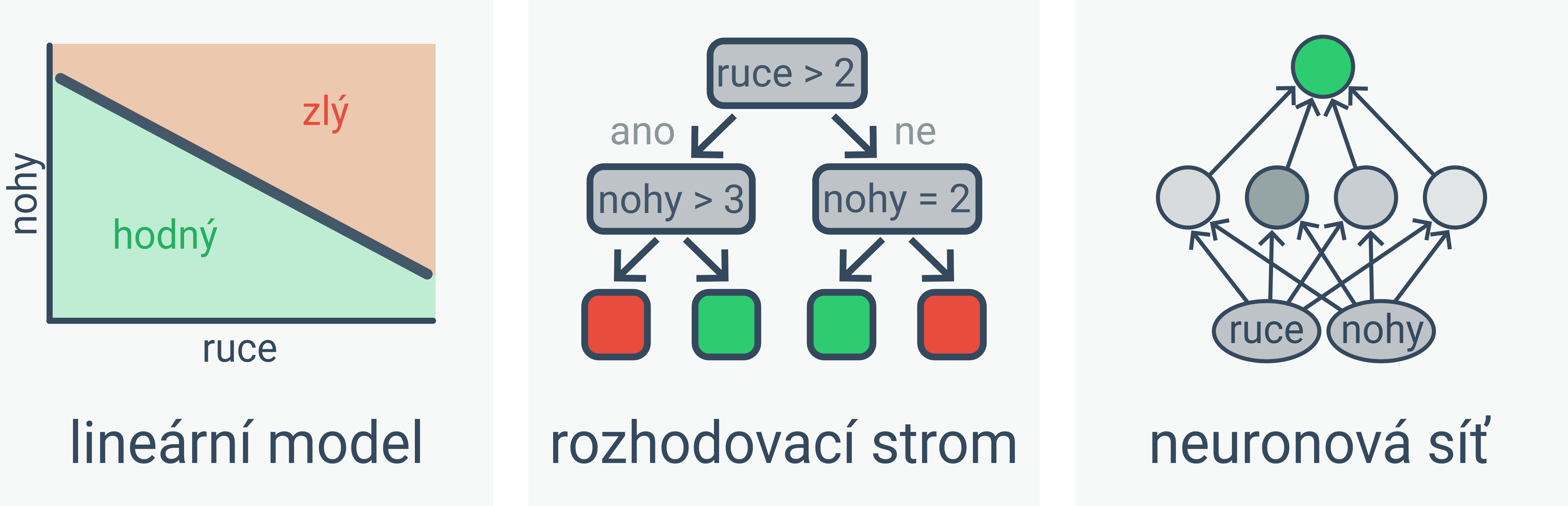
Volba vhodného modelu závisí například na množství dat a požadované interpretovatelnosti výstupů modelu. Neuronové sítě a jiné modely s mnoha parametry se umí naučit velmi složité funkce, ale vyžadují hodně dat a jsou hůře interpretovatelné než lineární modely a rozhodovací stromy.
Učicí algoritmy
Učicí algoritmus hledá strukturu nebo parametry modelu tak, aby minimalizoval zadanou chybu. Příkladem učicího algoritmu, který se využívá např. pro lineární modely a neuronové sítě, je gradientní sestup (angl. gradient descent). Při gradientním sestupu začneme s náhodnými hodnotami parametrů a ty pak opakovaně upravujeme tak, abychom zmenšili chybu modelu. Jiný učicí algoritmus se používá pro budování rozhodovacích stromů: strom postupně zvětšujeme přidáváním rozhodovacích uzlů s podmínkami, které co nejlépe rozdělují příklady.
Příklad učení lineárního klasifikátoru příšerek
Parametry lineárního modelu jsou (a) váha pro počet rukou, (b) váha pro počet nohou a (c) hranice, při které je ještě příšerka klasifikovaná jako hodná: a \cdot \text{[počet rukou]} + b \cdot \text{[počet nohou]} < c
Například pro hodnoty parametrů a = 2, b = 4, c = 20 bude model klasifikovat příšerku jako hodnou tehdy, když 2 \cdot \text{[počet rukou]} + 4 \cdot \text{[počet nohou]} < 20.
Různá nastavení těchto parametrů vedou na různý počet chybně klasifikovaných příšerek. Řekněme, že při hodnotách parametrů a = 2, b = 4, c = 20 model klasifikuje chybně 20 % příšerek. Gradientní sestup by mohl parametry upravit na a = 2, b = 3, c = 18 a snížit tak chybu třeba na 15 %. Gradientní sestup by opakovaně prováděl takovéto drobné úpravy parametrů (spíše ještě drobnější).
Směr změny parametrů, který co nejvíce sníží chybu, závisí na konkrétní chybové funkci a pro mnohé chybové funkce lze tento směr (tzv. gradient) spočítat.
Postup strojového učení (těžké)
