Neuronová síť je výpočetní model volně inspirovaný fungováním mozku. Skládá se z mnoha propojených neuronů, které počítají jednoduché funkce. Protože je ale neuronů hodně, je výsledná funkce určená neuronovou sítí složitá.
Neurony
Každý neuron přijímá signál z několika jiných neuronů, signály zpracuje a výsledek posílá dál do napojených neuronů. Signálem putujícím mezi dvěma neurony je jedno reálné číslo. Jednotlivé neurony počítají vážený součet vstupů upravený nelineární aktivační funkcí (např. \max(\cdot, 0)), tj. y = g(\sum_i w_i x_i), kde g je aktivační funkce, w jsou váhy a x jsou vstupní hodnoty.
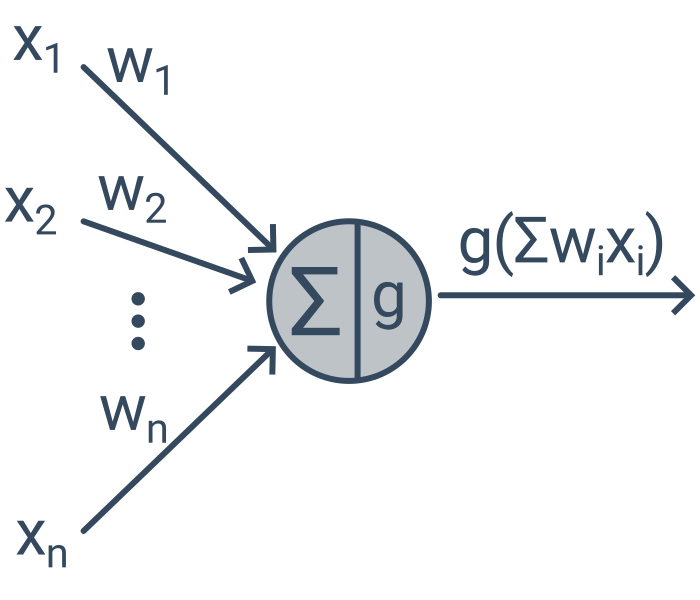
Perceptron je nejjednodušší neuronová síť – obsahuje jediný neuron. Taková síť je velmi podobná lineárnímu modelu. Většinou však neuronové sítě obsahují tisíce či miliony neuronů.
Struktura neuronové sítě
Neurony jsou typicky uspořádané do několika vrstev (vstupní, několik skrytých a nakonec výstupní). Příklad, o kterém chceme něco rozhodnout (např. obrázek, věta, stav hry), je zakódován pomocí hodnot neuronů ve vstupní vrstvě. Skryté vrstvy pak z příkladu extrahují postupně komplexnější vzory. (První skrytá vrstva například detekuje hrany a barevné pásy, druhá vrstva rohy a oblouky, další vrstva základní tvary, další vrstvy postup složitější tvary.) Výstupní vrstva pak obsahuje výslednou predikci (např. určení objektu na obrázku, pokračování rozepsané věty, vhodný tah). Pro neuronové sítě s mnoha vrstvami se používá označení hluboké.
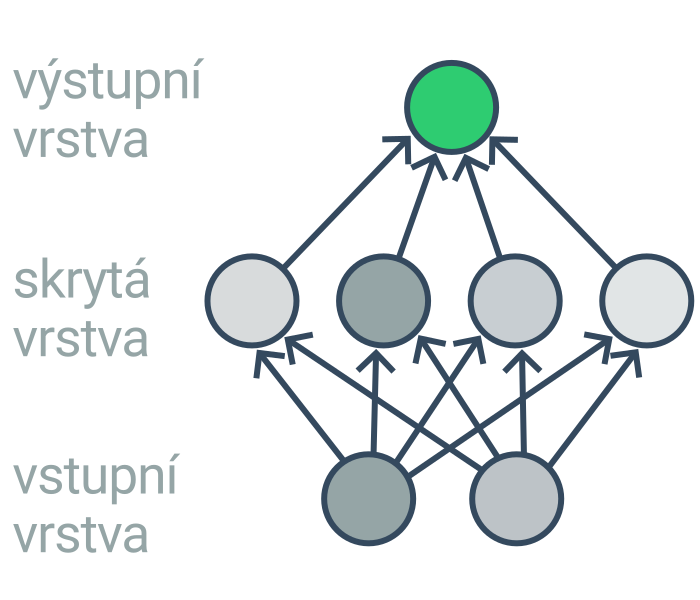
Základní architekturou je vícevrstvý perceptron, ve kterém jsou neurony v každé vrstvě propojeny se všemi neurony ve vrstvě následující. Alternativou jsou například konvoluční neuronové sítě, v nichž některé vrstvy provádí konvoluci – operaci, při které posouváme malý filtr přes celá data (např. každý pixel nahradíme váženým součtem pixelů v okolí). Konvoluční sítě se hodí na zpracování dat s prostorovou strukturou (např. obrázky).
Sítě, ve kterých informace putuje jedním směrem (tj. síť neobsahuje cykly) se označují jako dopředné. Opakem dopředných sítí jsou rekurentní neuronové sítě, které obsahují neurony, jejichž výstup je současně jejich vstupem (neuron má tedy v podstatě paměť). Rekurentní sítě se hodí pro zpracování sekvenčních dat (např. text). Výpočet a učení rekurentních neuronových sítí je však složitější než sítí dopředných.
Proto se v poslední době i pro sekvenční data častěji využívají transformátory, dopředné sítě, které transformují celé sekvence naráz a používají mechanismus pozornosti určující, na kterou část dosavadní sekvence se zaměřit. Transformátory se používají pro zpracování textu, zvuku i obrazu. (Např. GPT znamená „generativní předtrénovaný transformátor“.)
Učení neuronových sítí
Neuronová síť je v podstatě komplikovaná funkce s mnoha parametry (váhy mezi neurony). Učení sítě je optimalizační úloha hledání takových vah, které minimalizují chybu predikcí sítě na trénovacích datech. Příkladem chybové funkce je kvadratická chyba – součet druhých mocnin odchylek mezi predikovanou a skutečnou hodnotou (přes všechny příklady v trénovacích datech).
K učení se využívá algoritmus gradientního sestupu: začneme s náhodnými hodnotami parametrů a ty pak opakovaně upravujeme tak, abychom zmenšili chybu. Gradient je směr, ve kterém funkce nejrychleji roste, postupujeme tedy proti směru gradientu. Gradient lze spočítat algoritmem zpětného šíření chyby (angl. backpropagation): pro každý příklad v trénovací sadě provedeme dopředný výpočet sítě, porovnáme predikci se skutečností a upravíme všechny váhy (postupně od poslední k první vrstvě) tak, aby se chyba snížila.
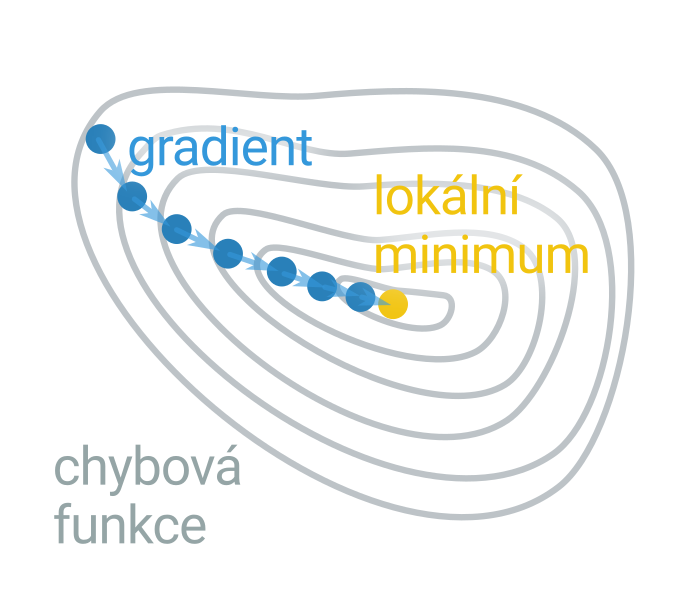
Učení hlubokých neuronových sítí je obtížné kvůli problému mizejícího gradientu – gradient exponenciálně klesá se vzdáleností neuronu od výstupu sítě. Výzkum v oblasti neuronových sítí přináší stále nové techniky, jak tento problém zmírnit, jako nejdůležitější se však ukazuje výpočetní výkon. Pro urychlení výpočtů se využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit), i tak však učení rozsáhlých modelů může trvat mnoho dní.
Neuronové sítě mají mnoho parametrů, hrozí proto riziko přeučení, kdy si síť pouze zapamatuje přesné odpovědi pro trénovací data, ale není schopna generalizovat na nové příklady. Pro učení neuronových sítí je proto potřeba velké množství příkladů a využití regularizačních technik, které riziko učení snižují (např. penalizace příliš vysokých vah).
Kromě vah v neuronové síti můžeme optimalizovat i její strukturu (např. počet vrstev) a parametry učení (např. velikost kroku při gradientním sestupu). Tyto speciální parametry ovlivňující ostatní parametry se označují jako hyperparametry. Jejich hodnota je během učení gradientním sestupem konstantní, můžeme je však optimalizovat mřížkovým prohledáváním, při kterém zkoušíme naučit síť pro různé volby hyperparametrů.
Využití
Neuronové sítě mají využití zejména v oblastech, kde je k dispozici velké množství dat k učení, je obtížné přesně popsat užitečné rysy příkladů manuálně a nepotřebujeme vysvětlení výsledných predikcí. Používají se pro zpracování přirozeného jazyka (odpovídání na otázky, strojový překlad, rozpoznávání řeči), počítačové vidění (klasifikace obrázků, generování obrázků, analýza medicínských měření), řízení a rozhodování (hraní šachů, řízení autonomních vozidel) a predikci struktury či budoucího vývoje (predikce 3D struktury proteinů, odhadování vývoje cen akcií).