- Základy strojového učení
 Všechna shrnutí
Všechna shrnutí
Předcházející
Navazující
Aby byl model užitečný, nestačí, aby si zapamatoval trénovací data. Musí být schopen určovat správný výstup i pro příklady nové, tedy generalizovat. Kvalitu modelu je proto potřeba vyhodnotit na datech, která model neviděl během učení, jinak bude vyhodnocení neoprávněně optimistické. Situaci, kdy si model zapamatuje přesné odpovědi pro trénovací data, ale není schopen generalizovat, nazýváme přeučení (někdy též přetrénování, angl. overfitting). Situaci, kdy je zvolený model příliš jednoduchý na danou úlohu, takže má vysokou chybu i na trénovacích datech, nazýváme podučení (někdy též podtrénování, angl. underfitting).

Složitější modely jsou typicky náchylnější k přeučení, protože se umí naučit libovolný šum v datech. Pokud jsou dva modely podobně správné na datech, která máme k dispozici, tak pro nová data bude proto pravděpodobněji lépe generalizovat ten jednodušší z nich. Jde o případ obecného principu zvaného Occamova břitva, který říká, že existuje-li více různých vysvětlení, je lépe upřednostňovat to jednodušší z nich.
Kvalitu modelů lze kvantifikovat pomocí různých metrik. Pro vyhodnocení regresních modelů se často používá střední kvadratická chyba (angl. mean squared error), což je průměrná druhá mocnina odchylky mezi predikovanou a skutečnou hodnotou. Pro vyhodnocení klasifikačních modelů se používá například správnost (angl. accuracy, podíl správných odpovědí), přesnost (angl. precision, kolik ze všech označených příkladů je pozitivních) a pokrytí (angl. recall, kolik ze všech pozitivních příkladů model detekoval).
Užitečnou vizualizací je matice záměn (angl. confusion matrix), která zobrazuje, kolik kterých kategorií bylo jak klasifikováno. Následující matice kompaktně zachycuje chování modelu pro predikci nemoci (P – pozitivní, N – negativní), kdy model v 9 případech správně predikoval pozitivní výsledek, v 87 správně predikoval negativní výsledek, v 1 případě chybně predikoval pozitivní výsledek a ve 3 případech chybně predikoval negativní výsledek.

Vždy je vhodné problém nejprve zkusit řešit pomocí jednoduchého základního modelu (angl. baseline), což může být například průměrná hodnota (pro regresi) nebo nejčastější kategorie (pro klasifikaci). Srovnání metrik složitějšího modelu se základním modelem umožňuje hodnoty metrik lépe interpretovat.
Rozhodovačka
Rychlé procvičování výběrem ze dvou možností.

Vyhodnocení strojového učení (střední) • NDK
Typicky zabere: 7 min
Vyhodnocení strojového učení (těžké) • NDV
Typicky zabere: 5 min
Přesouvání
Přesouvání kartiček na správné místo. Jednoduché ovládání, zajímavé a neotřelé úlohy.
Vyhodnocení strojového učení (střední) • NEB
Typicky zabere: 7 min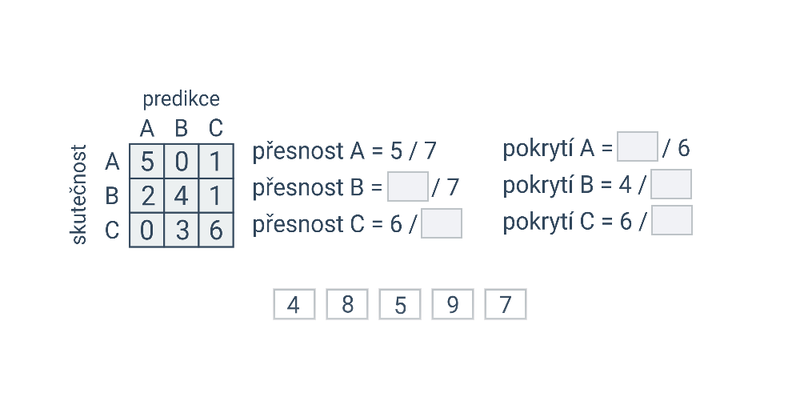
Pexeso
Hledání dvojic, které k sobě patří.
Vyhodnocení strojového učení (těžké) • NZP
Typicky zabere: 5 min
Krok po kroku
Doplňování jednotlivých kroků v rozsáhlejším postupu.
Vyhodnocení strojového učení (střední) • NDZ
Typicky zabere: 5 min
Porozumění
Čtení textů, odpovídání na otázky testující porozumění textu.


