Výpis shrnutí
Kódování a modelování
Podtémata
- Kódování a modelování
- Kódování informací
- Kódování informací obrázkem
- Kódování informací textem i jinak
- Kódování textu a šifrování
- Základní kódování textu
- Kódování textu v počítačích
- Základní šifry
- Šifry s nápadem
- Šifrování: pojmy a principy
- Kódování obrazu a zvuku
- Bitmapová grafika
- Vektorová grafika
- Bitmapová vs. vektorová grafika
- Reprezentace barev
- RGB barvy
- Kódování zvuku
- Kódování čísel
- Binární čísla: základy
- Bity a bajty
- Záporná a desetinná binární čísla
- Počítání v binární soustavě
- Bitové operace
- Hexadecimální čísla
- Přenos a komprese dat
- Informace, velikost dat
- Komprese dat
- Přenos dat
- Modelování pomocí grafů
- Grafy a abstrakce
- Grafy: nejkratší cesty
- Shodné grafy
- Teorie grafů: základní pojmy
- Teorie grafů: vlastnosti a části grafů
- Modelování vztahů a systémů
- Vlastnosti a vztahy
- Typy vztahů
- Entitně-vztahové modely
- Modelování a simulace
- Modely a skutečnost
- Použití modelů a simulací
- Zpětné vazby
- Interpretace simulací
Kódování a modelování
V informatice pracujeme s informacemi o světě kolem nás. Abychom s informacemi mohli pracovat, musíme je umět nějakým způsobem přesně zachytit. Informace lze kódovat mnoha způsoby, od piktogramů až po binární čísla. Zatímco kódování se zabývá především tím jak informace zachytit, modelování se zabývá i tím co chceme zachytit. Model je zjednodušené znázornění skutečnosti.
Příklady kódování
- Dopravní značky jsou obrázky, které kódují informace typu „zákaz vjezdu“ či „dej přednost v jízdě“.
- Binární soustava kóduje čísla jako posloupnost nul a jedniček.
- Barvy v obrázku můžeme kódovat pomocí trojice čísel vyznačujících podíl červené, zelené a modré složky.
- Morseova abeceda kóduje písmena pomocí teček a čárek.
- Kódování informací – jednoduché, intuitivní ukázky kódování, především pomocí obrázků
- Kódování textu a šifrování – historická kódování textu (např. Morseova abeceda), současná kódování textu v počítačích, šifrování
- Kódování obrazu a zvuku – bitmapová a vektorová grafika, reprezentace barev, kódování zvuku
- Kódování čísel – binární a hexadecimální soustava
- Přenos a komprese dat – kódování dat za účelem jejich zmenšení a bezchybného přenosu
- Modelování pomocí grafů – modelování systémů pomocí uzlů a hran, hledání nejkratších cest
- Modelování vztahů a systémů – vlastnosti, vztahy, úplné základy i entitně-vztahové diagramy
- Modelování a simulace – obecné principy modelování, využití počítačů pro dynamické simulace
Výukové moduly
Konkrétní náměty, jakým způsobem učivo procvičovat a v jakém pořadí, poskytují výukové moduly:
| 4.–6. ročník | Základní úvod do kódování informací a šifrování za využití intuitivních příkladů. | |
| 6.–8. ročník | Princip modelování na příkladě grafů, obecnější principy modelování, názorné ukázky simulací. |
Kódování informací
Tato sekce ilustruje základní principy kódování na jednoduchých příkladech:
- Kódování informací obrázkem – dopravní značky, turistické značky, ikonky, symboly pro předpověď počasí
- Emodži a Unicode symboly – kódování textu, symbolů a malých ikonek
- Kódování informací textem i jinak – pohled na text (a další způsoby zápisu informací) jako na kódování informace
Navazující témata pak už detailněji probírají technické principy kódování:
NahoruKódování informací obrázkem

Informace o světě potřebujeme nějak zaznamenávat (kódovat). Typický způsob takového záznamu je pomocí písma. Pokud například máme jít v úterý v 9:00 k zubaři, zakódujeme si tuto informaci do diáře pomocí slova „zubař“. To ale není jediný možný způsob. Místo psaní slova bychom si mohli do diáře nakreslit obrázek zubaře.
Kódování informací pomocí obrázků se používalo jako předstupeň písma. Ale obrázky nejsou jen pro pračlověky, kteří si do svého kamenného diáře potřebují vytesat obrázek zubaře. I dnes, kdy již hodně používáme písmo, má stále kódování informací pomocí obrázků svůj smysl. Obrázky jsou totiž často přehlednější.
Mezi typické příklady kódování informace obrázkem patří:
- dopravní značky
- turistické mapové značky
- symboly označující předpověď počasí
- symboly označující sporty na olympiádě
- ikonky v počítačových programech
Kromě níže uvedených interaktivních cvičení je k dispozici také pomůcka pro aktivity – kartičky určené k vytištění, rozstříhání a párování (náměty k využití nabízí stránka Aktivity s kartičkami):
Nahoru
Kódování informací textem i jinak
Jeden z nejjednodušších způsobů kódování informací je pomocí textu. Například pokud máme jít k zubaři, bude pravděpodobně jednodušší napsat si do kalendáře „zubař“ místo kreslení obrázku zubaře. Nakreslit obrázek bude trvat o něco déle a rozluštit obrázek může být těžší, pokud jsme kreslení zubařů zatím moc netrénovali.
Způsoby kódování pomocí textu
Zakódovat jednu informaci do textu jde mnoha různými způsoby. Třeba bychom si místo prostého hesla zubař mohli zapsat Nezapomeň, že zítra máš jít na kontrolu k zubaři. Často stačí zaznamenat si jenom zásadní informace, ostatní můžeme většinou odvodit z kontextu nebo našich znalostí o světě. Díky tomu je často kód (zápis) výrazně stručnější než samotná informace, kterou zaznamenává.
Je ale potřeba dobře určit, které informace ještě můžeme vynechat a které už ne. Například pokud si do kalendáře zapíšeme DÚ Staré pověsti, za týden si už nemusíme pamatovat, v čem přesně vlastně úkol spočíval. A pokud by tento zápis po nás četl někdo jiný, nebude ani vědět, o které pověsti přesně jde.
Příklady kódování pomocí textu
- Když píšeme na dopis adresu, kódujeme, kam má dopis být doručen.
- Když si píšeme s kamarádem textové zprávy, kódujeme nejen to, co bychom vyprávěli, ale třeba i to, jak bychom se tvářili.
- Názvy na obchodech kódují, co pravděpodobně v daném obchodu seženeme.
- Text v knize kóduje příběh, pocity a spoustu dalšího, co se nám kniha snaží předat.
Další způsoby kódování
Text sám o sobě ale občas nestačí, takže se často hodí ho kombinovat s jinými způsoby kódování. Důležitou informaci v sešitě můžeme od ostatních barevně odlišit nebo ji podtrhnout. V mapách se kombinuje text s různými značkami a barvami. A pokud k nápisu „Nouzový východ“ přidáme i obrázek, může být lépe vidět a navíc ho mohou najít i cizinci, kteří by nerozuměli českým slovům.
Další příklady kódování z běžného života
- Dopravní značky: Barvy, tvary a symboly na dopravních značkách kódují informace o silnici, dopravních pravidlech a nebezpečích.
- Noty: Hudební notace kóduje zvuky, rytmus a hlasitost hudby pomocí not a dalších symbolů.
- Čárové kódy na produktech: Čárové kódy na produktech v obchodě kódují informace o ceně a produktu.
Kódování textu a šifrování
Kódování i šifrování mají společné to, že mění podobu textu. Mají však jiný účel. Cílem šifrování je uchování tajemství. Cílem kódování není utajení, pouze spolehlivý záznam či přenos zprávy.
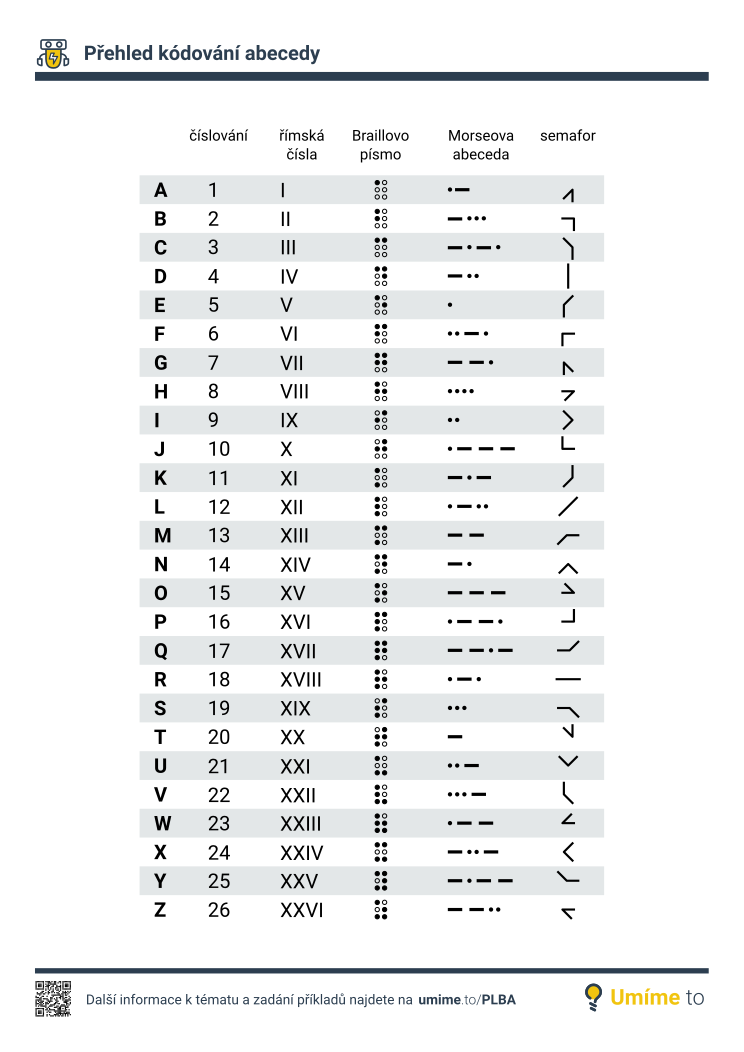
Základní kódování textu bylo využíváno ještě před příchodem počítačů. Například Morseova abeceda se používala pro přenos zpráv telegrafem a Braillovo písmo kóduje text pro čtení hmatem. Pro kódování textu v počítačích se používají metody založené na binárních číslech (nuly a jedničky).
Kódování zprávu neutají. Pokud zapíšeme zprávu PES pomocí Morseovy abecedy (.−−.|.|…), tak každý, kdo tuto abecedu zná, si může zprávu snadno přečíst. K utajení zprávy slouží šifrování. Lidé rádi něco tají, takže šifrování se používá skoro tak dlouho jako psaní. Již ve starověku se šifrování hojně používalo, známá je například Caesarova šifra. Šifrování hrálo mnohokrát důležitou roli v dějinách, klíčovou událostí bylo například v průběhu druhé světové války prolomení německého šifrovacího stroje Enigma.
Šifrování hraje důležitou roli i dnes. Bez kvalitních šifer by například nebylo možné elektronické obchodování. Každý uživatel internetu pravidelně používá šifrování, i když o tom třeba vůbec neví, protože šifrování provádí automaticky webový prohlížeč.
Téma šifrování si můžete procvičit několika způsoby:
- Základní šifry – základní principy šifrování (transpozice, substituce) ilustrované na jednoduchých příkladech.
- Šifry s nápadem – tyto šifry se nepoužívají pro praktické účely, ale dobře poslouží jako trénink myšlení a test základních kryptoanalytických dovedností.
- Šifrování: pojmy a principy – pokročilejší téma, které se zabývá přesněji způsoby použití šifrování a hlavními pojmy.
K tématu šifer máme připraveny také pracovní listy. Jejich přehled a tipy k využití najdete na samostatné stránce Šifry: pracovní listy.
Pokud si chcete vygenerovat vlastní šifry, můžete využít šifrátor.
NahoruZákladní kódování textu
Informace běžně kódujeme jako text, který zapisujeme na papír pomocí písmen abecedy. Zápis pomocí písmen na papír ale není jediný způsob, jak můžeme text zakódovat.
- Morseova abeceda přiřazuje každému písmenu kód, který se skládá z teček a čárek. Používala se dříve především pro přenos informací telegrafem.
- V námořní vlajkové abecedě má každé písmeno svoji vlajku. Text se kóduje jako řada vlajek.
- V semaforové abecedě vysílající kóduje písmena pomocí různých pozic rukou, ve kterých drží barevné praporky. Stejně jako námořní vlajková abeceda má využití například mezi námořníky pro komunikaci na dálku.
- Braillovo písmo kóduje písmena pomocí hrbolků v mřížce 2×3. Toto písmo je určeno pro lidi s postižením zraku pro čtení hmatem.
- Počítače ukládají písmena pomocí číselných kódů. Kódování textu v počítačích se věnuje samostatné téma.
Pracovní listy
Kromě interaktivních cvičení jsou k dispozici také následující pomůcky k vytištění a pracovní listy:

K využití šifer s kódováním se vztahují rady uvedené na stránce Šifry: pracovní listy.
NahoruKódování textu v počítačích
V počítači jsou všechny informace uloženy jako nuly a jedničky. Pro uložení textové informace tedy potřebujeme kódování, které text převede na nuly a jedničky. V 60. letech 20. století za tímto účelem vznikla ASCII tabulka, která znakům přiřazovala čísla od 0 do 127 a tato čísla se následně zapsala v binární soustavě do jednoho bajtu.
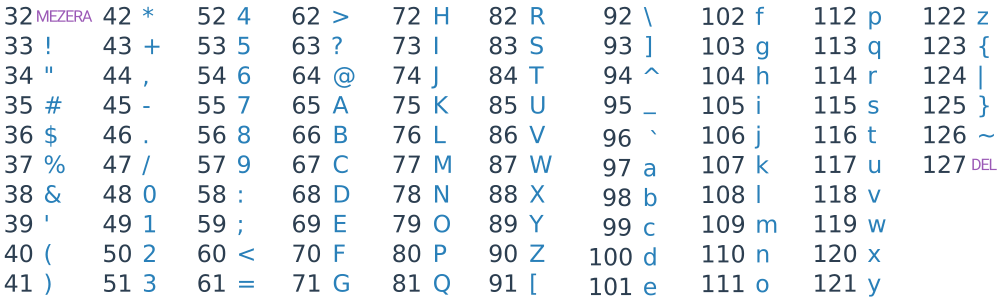
ASCII kódování však umožňovalo kódovat pouze písmena anglické abecedy a některé další základní znaky. Proto byl později vyvinut standard Unicode, který umožňuje zápis nejen základních písmen, ale i jiných světových abeced a mnoha dalších symbolů (např. sněhuláka: ☃). Jaké další znaky se v Unicode nacházejí, můžete prozkoumat zde. Zatímco Unicode přiřazuje znakům čísla, různá kódování (např. UTF-8) určují, jak tato čísla převést na jedničky a nuly, které se uloží v počítači.
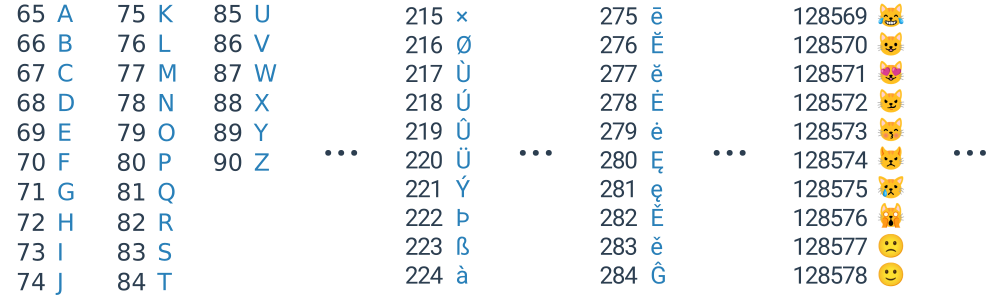
Příklad kódování sněhuláka
Unicode kóduje sněhuláka jako číslo 2603 v šestnáctkové soustavě.
Základní šifry
Transpoziční šifry
Transpoziční šifry mění pouze pořadí písmen, nikoliv jejich vzhled. Základní transpoziční šifry jsou založeny na přepsání textu do řádku nebo do mřížky podle jednoduchého principu. Příklady:
- zápis pozpátku (JABLONEC → CENOLBAJ)
- zápis ob jedno písmeno (JABLONEC → JOANBELC)
- prohazování sousedních písmen (JABLONEC → AJLBNOCE)
- šifrovací mřížka
Existují i složitější transpoziční šifry, které umožňují šifrovat podle hesla.
Substituční šifry
Substituční šifry naopak zachovávají pořadí písmen, ale mění jejich podobu. Základní substituční šifrou je posun v abecedě (nazývaný též Caesarova šifra), kdy písmena nahrazujeme za jiná písmena, např. při posunu o jedna zašifrujeme BRNO → CSOP (B se posune na C, R se posune na S a tak dále). Složitějším příkladem substituční šifry je šifrování podle hesla (Vigenèrova šifra).
Podobné substitučním šifrám je kódování, např. Morseova abeceda, Braillovo písmo, či ASCII tabulka. Kódování samo o sobě však není šifrou, protože zprávu neutají. Když zapíšeme zprávu pomocí Morseovy abecedy, tak každý, kdo tuto abecedu zná, si ji snadno může přečíst.
Pracovní listy
Kromě interaktivních cvičení jsou k dispozici také pracovní listy k tématu šifer:
- Transpoziční šifry + řešení. Zadání obsahuje 9 šifer, každá z nich skrývá jedno přísloví. V zadání jsou uvedeny schematické nápovědy. Pro zkušenější luštitele je možné nápovědy odstřihnout.
- Substituční šifry + řešení. Obsahuje zadání na Caesarovu šifru, obrázkovou substituci i šifrování podle hesla. Pracovní list uvádí i stručné návody k principům, takže s trochu hloubání je řešitelné i bez předchozí znalosti těchto principů.
Další pracovní listy se šiframi a tipy k jejich využití obsahuje stránka Šifry: pracovní listy.
NahoruŠifry s nápadem
Při praktických aplikacích šifrování je typicky základní šifrovací princip známý a bezpečnost šifry je založena na utajení klíče. V následujících cvičeních si můžete zkusit šifry, k jejichž vyluštění musíte odhalit jejich šifrovací princip. Takové šifry slouží především pro zábavu, využívají se například hojně v šifrovacích hrách, pokladovkách a soutěžích. I přesto, že tyto šifry nemají přímé praktické použití, můžete se na nich dobře procvičit principy základních šifer, ale i logické myšlení, hledání vzorů a trpělivost.
Pracovní listy
Kromě interaktivních cvičení je k dispozici také pracovní listy k tématu:

Další pracovní listy se šiframi a tipy k jejich využití obsahuje stránka Šifry: pracovní listy.
NahoruŠifrování: pojmy a principy
Základní situace
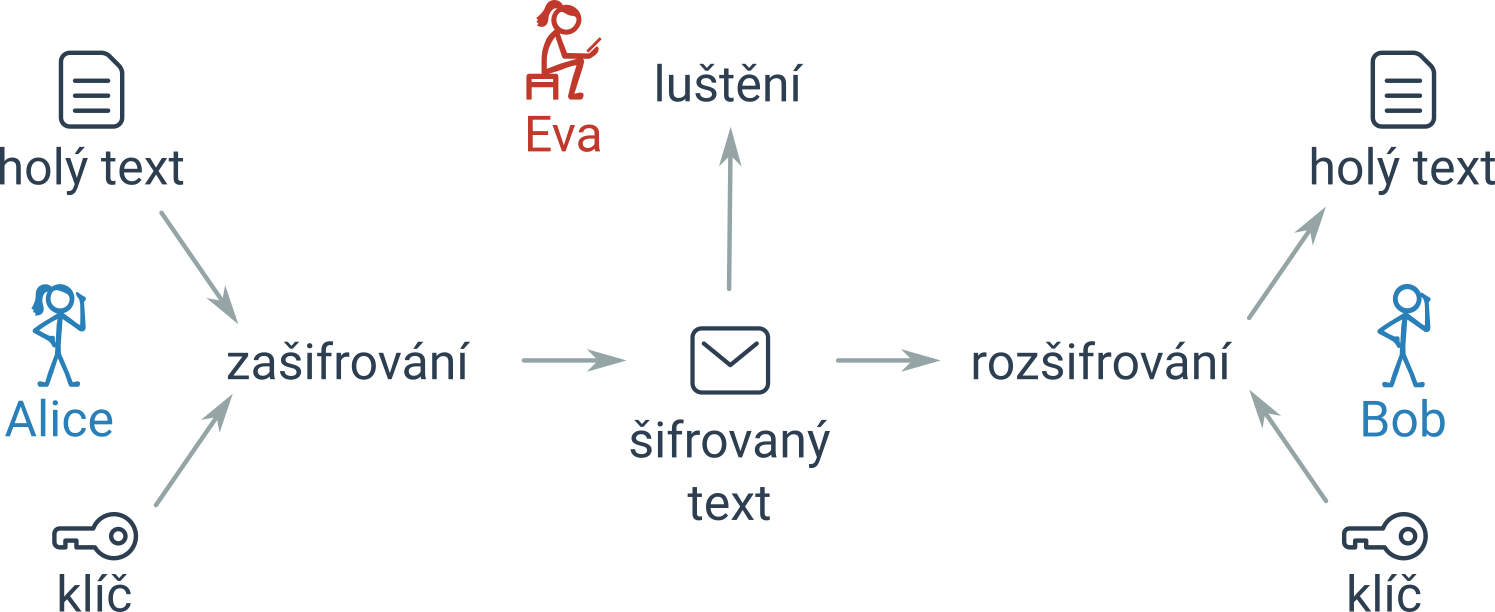
Účelem šifrování je utajit zprávu. Obrázek znázorňuje základní situaci: Alice chce poslat Bobovi zprávu. Text této zprávy nazýváme holý text. Tento holý text Alice zašifruje pomocí předem domluveného šifrovacího postupu a tajného klíče. Tím vznikne zašifrovaný text, který Alice pošle Bobovi. Bob zašifrovaný text pomocí klíče rozšifruje a může si přečíst zprávu.
Šifrovaný text může někdo zachytit (na obrázku je to Eva). Eva se může pokusit zprávu odhalit, má to ale těžké, protože nezná tajný klíč (a případně ani použitý šifrovací princip). Provádí tedy luštění, které je o kus náročnější než rozšifrování.
Pojmy
- Kryptologie je odborný název pro šifrování a luštění šifer. Dvě hlavní části kryptologie jsou kryptografie a kryptoanalýza.
- Kryptografie se zabývá samotnými šifrovacími postupy, které používají ti, kdo spolu chtějí utajeně komunikovat (na obrázku Alice a Bob).
- Kryptoanalýza se zabývá tím, co dělá na obrázku Eva, tedy jak vyluštit zachycenou zprávu, u které neznáme šifrovací klíč či způsob zašifrování.
Typy šifer
- Transpozice mění pouze pořadí písmen, nikoliv jejich vzhled.
- Substituce zachovává pořadí písmen, ale mění jejich podobu.
- Monoalfabetická substituce nahrazuje jedno písmeno vždy za stejný znak. Příkladem je Caesarova šifra (posun v abecedě).
- Polyalfabetická substituce nahrazuje písmeno za různé znaky v závislosti na poloze v textu. Příkladem je Vigenèrova šifra
- Steganografie je snaha o úplné utajení existence zprávy, například pomocí neviditelného inkoustu nebo nenápadném skrytí textu v obrázku.
Metody kryptoanalýzy (prolomení šifer)
Útok hrubou silou spočívá ve vyzkoušení všech možných klíčů.
Frekvenční analýza spočívá v analýze frekvencí (četností) znaků ve zprávě. Tento způsob analýzy šifer je založen na využití toho, že písmena v jazyce jsou zastoupena velmi nerovnoměrně, např. v češtině je písmeno E velmi časté, zatímco F málo časté.
Moderní šifry
Moderní šifry jsou výrazně složitější než zápis pozpátku či posun v abecedě, typicky využívají pokročilou matematiku a složité algoritmy. Příkladem moderní šifry je RSA.
Moderní šifry jsou dvou základních typů:
- Symetrické šifry využívají pro šifrování i dešifrování stejný tajný klíč (stejně jako na výše uvedeném obrázku s Alicí a Bobem).
- Asymetrické šifry využívají pro zašifrování veřejný klíč a pro dešifrování tajný soukromý klíč. Tyto šifry lze využít i pro realizaci elektronického podpisu.
Kódování obrazu a zvuku
Abychom mohli na počítači pracovat s multimediálním obsahem (obraz, zvuk, video), musíme jej umět zakódovat pomocí čísel.
- Bitmapová grafika – S obrázkem pracujeme jako s mřížkou pixelů, kde každý z nich má přidělenou svoji barvu.
- Vektorová grafika – Obrázky jsou tvořeny z geometrických útvarů (např. úseček, kružnic, křivek).
- Bitmapová vs. vektorová grafika – Každý z těchto způsobů má své využití a je důležité mezi nimi dobře rozlišovat (např. fotografii většinou reprezentujeme bitmapově, kdežto logo firmy vektorově).
- Reprezentace barev – Při práci s obrazem potřebujeme umět zakódovat barvy číselně.
- RGB barvy – RGB je jeden z nejčastěji používaných způsobů kódování barev.
- Kódování zvuku – Zvuk se kóduje jako posloupnost amplitud (výchylek) zvukového signálu.
Bitmapová grafika
V bitmapové (rastrové) grafice jsou obrázky ukládány jako mřížka pixelů. Pixely jsou body, které mají danou polohu v obrázku a barvu. Barvy v pixelech kódujeme nějakým předem daným způsobem, často se používá např. RGB model. Čím jemnější je mřížka (čím víc pixelů obrázek obsahuje), tím kvalitnější a detailnější bude obraz. Protože pixely nelze dále rozdělovat, při zvětšování bitmapového obrázku se budou zvětšovat i pixely a dojde ke ztrátě kvality. Na obrázku vidíme, jak je možné uložit obrázek kruhu na malém počtu pixelů.
![]()
Barevná hloubka je počet barev, kterých může nabývat jeden pixel. Čím větší je barevná hloubka, tím více barev máme k dispozici a obraz tak může být kvalitnější. Na obrázku je vidět rozdíl mezi situacemi, kdy jsou k dispozici 2 barvy, 4 barvy a 256 barev.

Velikost bitmapového obrázku je určena počtem pixelů. Obrázek s rozměry 1024 × 1024 obsahuje 1024 \cdot 1024 (přibližně milion) pixelů a jeho velikost je 1 Mpx (megapixel). Rozlišení je hodnota, která říká, jak detailní je obraz. Udává se v jednotkách DPI (dots per inch).
NahoruVektorová grafika
Ve vektorové grafice jsou obrázky tvořeny z geometrických útvarů, například mnohoúhelníků, kružnic, křivek, lomených čar aj. Vektorově je možné popsat i text. Jednotlivé objekty jsou popsány různými číselnými a textovými parametry (např. poloha v souřadnicích, velikost, barva). Abychom si vektorový obrázek mohli zobrazit, počítač musí pokaždé interpretovat textový popis objektů a obrázek vykreslit. Díky vektorovému popisu objektů lze vektorové obrázky snadno zvětšovat a zmenšovat, aniž by byla jakkoli ovlivněna kvalita obrazu.
Vektorové obrázky se často ukládají ve formátu SVG. Textová reprezentace jednoduchého tvaru ve formátu SVG může vypadat následovně.
Prvně specifikujeme, o jaký typ objektu jde: circle znamená anglicky kruh. Následují různé parametry, které určují, jak přesně má tento kruh vypadat. Parametry cx a cy definují pozici středu kruhu na souřadnicích (60, 60) v obrázku. Parametr r určuje poloměr kruhu a v parametru fill je specifikována barva výplně jako zelená. Vykreslený obrázek tedy bude vypadat takto:

V SVG formátu lze kódovat i mnoho jiných typů objektů, například rect (rectangle = obdélník), polygon (mnohoúhelník) nebo line (linka). U každého typu objektu specifikujeme různé parametry – velikost obdélníku například určíme výškou a šířkou. Pokud však budeme vytvářet vlastní vektorové obrázky, nemusíme vše psát textově – existují počítačové programy, které nám umožní pouze pracovat s objekty a textový kód napíší za nás.
Bitmapová vs. vektorová grafika
Existují 2 základní typy kódování obrazu: vektorová a bitmapová grafika. Bitmapové obrázky se skládají z pixelů (barevných bodů), vektorové z geometrických objektů. Formáty využívající bitmapovou grafiku jsou například BMP, JPG, PNG a GIF. Nejpoužívanějším vektorovým formátem je SVG, vektorovou reprezentaci používá také formát PDF.
Bitmapová grafika je ideální pro ukládání fotografií, protože digitální fotoaparáty také snímají obraz jako mřížku barevných bodů. Vektorová grafika je pro tento účel naopak nevhodná, protože fotografie bývá velmi těžké popsat pomocí geometrických útvarů.
Pro obrázky složené z geometrických tvarů (např. loga, diagramy, ilustrace) je naopak vhodná vektorová grafika. Její zásadní výhodou je dobrá škálovatelnost (snadné zvětšování a zmenšování obrázků bez vlivu na jejich kvalitu). Bitmapová grafika je vždy omezená počtem pixelů, nemůžeme tedy získat větší detaily než jednotlivé pixely. Geometricky popsané útvary však můžeme zvětšovat libovolně. Proto se vektorová grafika často využívá i ve webdesignu, protože u webových stránek je vhodné, aby se velikostí uměly přizpůsobit různým zařízením a velikostem obrazovek.
Na obrázku můžeme vidět rozdíl při zvětšování. Levý trojúhelník byl uložen bitmapově, pravý vektorově.

Pokud obrázek obsahuje jednoduché tvary, obsadí jeho vektorová reprezentace méně místa v paměti počítače než bitmapová. Pro velmi členité tvary nebo pro fotografie však bude vektorový popis natolik složitý, že velikost bitmapového souboru bude menší.
NahoruReprezentace barev
Reprezentace barev je klíčová pro mnoho oblastí, např. webdesign, digitální fotografie, video, tisk. Existuje několik různých barevných modelů, z nichž nejčastější jsou RGB, CMYK a HSL.
RGB (Red-Green-Blue) model se používá pro digitální displeje, kde se barvy zobrazují jako kombinace tří základních barev – červené, zelené a modré. Každá z těchto barev má číselnou hodnotu v rozsahu 0–255. RGB kódy se často zapisují pomocí hexadecimálních čísel. Protože toto kódování je velmi často využíváno v grafických programech, hodí se mít alespoň základní intuici, jakým barvám odpovídají různé RGB kódy.
CMYK (Cyan-Magenta-Yellow-Key) model se používá pro tisk, kde se barvy tvoří mícháním tří základních barev – azurové, purpurové a žluté – s černou.
HSL (Hue-Saturation-Lightness) model umožňuje reprezentovat barvy pomocí tří parametrů – odstín, sytost a jas. Odstín se mění v rozsahu 0–360 stupňů, sytost určuje intenzitu barvy a jas určuje světlost nebo tmavost barvy. Tento model umožňuje jednoduché úpravy barev, jako je změna jasu nebo sytosti.
NahoruRGB barvy
Barevný model RGB je způsob reprezentace barev pomocí tří složek: červená (red, R), zelená (green, G), modrá (blue, B). Jde o aditivní způsob míchání barev – jednotlivé složky barev se sčítají a vytvářejí světlo větší intenzity (světlejší barvu).

Při použití RGB modelu tedy barvu zapisujeme jako trojici čísel. Pro zápis hodnoty jednotlivých složek se používá mnoho různých zápisů. Například oranžovou barvu můžeme zapsat jako:
- RGB(255, 160, 64) = dekadický zápis osmibitového čísla
- #FFA040 = hexadecimální zápis
- RGB(100%, 63%, 25%) = barevné složky v procentech
- RGB(1, 0.63, 0.25) = barevné složky jako čísla od 0 do 1
Často používaný zápis je dekadický zápis osmibitového čísla, tj. číslice od 0 do 255.
Příklady barev z RGB zápisu
| RGB(0, 0, 0) | černá |
| RGB(255, 0, 0) | červená |
| RGB(100, 0, 0) | tmavá červená |
| RGB(0, 255, 0) | zelená |
| RGB(0, 0, 255) | modrá |
| RGB(255, 255, 0) | žlutá |
| RGB(255, 0, 255) | purpurová |
| RGB(0, 255, 255) | azurová |
| RGB(150, 150, 150) | šedá |
| RGB(255, 255, 255) | bílá |
Kódování zvuku
Základní principy
Zvuk je mechanické vlnění prostředí (typicky vzduchu) o frekvenci asi 20 Hz – 20 000 Hz. Vyšší frekvence sluch vnímá jako vyšší tóny.
Při nahrávání zvuku do digitálního zařízení je mechanické vlnění vzduchu převedeno mikrofonem na elektrické napětí. A/D převodník tento spojitý signál převede na binární data. Při přehrávání zvuku se data D/A převodníkem přemění na analogový signál. Jeho výkon se zvětší zesilovačem a může dojít k jeho přehrání reproduktorem, který chvěním membrány opět rozechvěje vzduch.
Kódování zvukové vlny
Vlnění vzduchu je spojité, v každém okamžiku má určitou hodnotu okamžité výchylky. Souvislý je i analogový signál, který je vytvářen např. mikrofonem. Spojitý průběh zvukové vlny je na obrázku znázorněn oranžově. Vodorovná osa vyjadřuje čas, svislá osa okamžitou výchylku signálu.

Digitální zařízení nedokážou zpracovat informaci o zvuku v nekonečném množství okamžiků. Při převádění analogového signálu na digitální se tedy provádí tzv. vzorkování – signál se převede na nespojitý (diskrétní), ten během určitého času vystřídá omezený počet hodnot (na obrázku vyjádřeno modrými body). To souvisí se vzorkovací frekvencí, např. při vzorkovací frekvenci 48 kHz se během sekundy vystřídá 48 000 hodnot vzorku.
Ani okamžitá výchylka signálu nemůže mít neomezené množství hodnot, proto se provádí tzv. kvantování, které souvisí s rozlišením vzorku. Např. rozlišení (vzorku) 4 bit znamená, že okamžitá výchylka vzorku může nabývat 2⁴ = 16 stavů (vizte obrázek).
Při ztrátové kompresi má význam hodnota bitrate (značí přenosovou rychlost). Čím větší je bitrate, tím větším množstvím dat je popsána sekunda zvukového záznamu (např. 320 kb/s je nejvyšší bitrate u souborů mp3).
Kódování tónů
Kromě kompletního záznamu zvukových vln (popsaného výše) může být zvuk reprezentován jako sekvence tónů. To se využívá zejména při skládání hudby či v souvislosti s rozhraním MIDI. V rámci sekvence mohou mít tóny např. různou výšku, délku, hlasitost aj. Těmto tónům je potom „přiřazen“ určitý zvuk, ať už ve formě vzorku či generovaný syntezátorem. Zvuk reprezentovaný jako sekvence tónů (ve formátu MID) se historicky používal např. jako hudební doprovod počítačových her. V současnosti se využívá spíše pro práci se zvukem, výsledné skladby jsou následně vyexportovány ve formě běžného záznamu digitálního signálu.
NahoruKódování čísel
Všechna data v počítači jsou reprezentovaná posloupností 0 a 1, tzv. bitů. Proto se čísla v počítačích kódují pomocí binární (dvojkové) soutavy, která využívá pouze 0 a1.
Jiné způsoby kódování čísel
V běžném životě jsme zvyklí zapisovat čísla v desítkové soustavě, ve které používáme deset různých cifer a jejich pozice odpovídá mocninám desítky. Tedy například 358 značí 8 jednotek, 5 desítek a 3 stovky. To je jeden z mnoha možných způsobů kódování.
Jak bychom mohli zakódovat 358 jinak? Třeba tak, že bychom udělali 358 čárek vedle sebe. Nebo bychom se mohli domluvit, že drak bude znamenat 100, prase 50 a zajíc 2. Potom bychom 358 mohli znázornit obrázkem, na kterém budou tři draci, prase a čtyři zajíci.
Počítače umí dobře rozlišovat mezi dvěma stavy (aktivní a neaktivní), proto používají binární (dvojkovou) soustavu. Kromě binární soustavy v informatice občas narazíme i na soustavy založené na mocninách dvojky, například osmičkovou či šestnáctkovou (hexadecimální) soustavu. S hexadecimálním zápisem čísel se můžeme potkat při práci s RGB barvami.
Témata
- Binární čísla: základy – Základní princip binární soustavy není nijak specifický pro počítače. Procvičíte si zde převod mezi desítkovou a binární soustavou.
- Bity a bajty – Specifika reprezentace binárních čísel v počítači, například určení, kolik bitů paměti potřebujeme.
- Záporná a desetinná binární čísla – Téma představuje různé způsoby, jak rozšířit binární zápis na záporná a desetinná čísla.
- Počítání v binární soustavě – Sčítání, odčítání a násobení binárních čísel funguje podobně jako počítání v desítkové soustavě.
- Bitové operace – Propojení binárních čísel s tématem logiky skrze logické operace nad všemi bity současně.
- Hexadecimální čísla – V informatice se lze setkat i s šestnáckovou (hexadecimální) soustavou, která používá 16 symbolů (0–9, A–F).
Binární čísla: základy
V binární (dvojkové) soustavě zapisujeme čísla pouze pomocí dvou číslic: 0 a 1. Pozice každé číslice v zápisu odpovídá určité mocnině dvojky. Mocniny vždy začínají nultou mocninou u číslice nejvíc vpravo a zvyšují se směrem doleva. Hodnotu binárního čísla pak spočteme jako součet těchto mocnin. Každou mocninu započítáme, pokud je na příslušné pozici 1 nebo nezapočítáme, pokud je na daném místě 0.
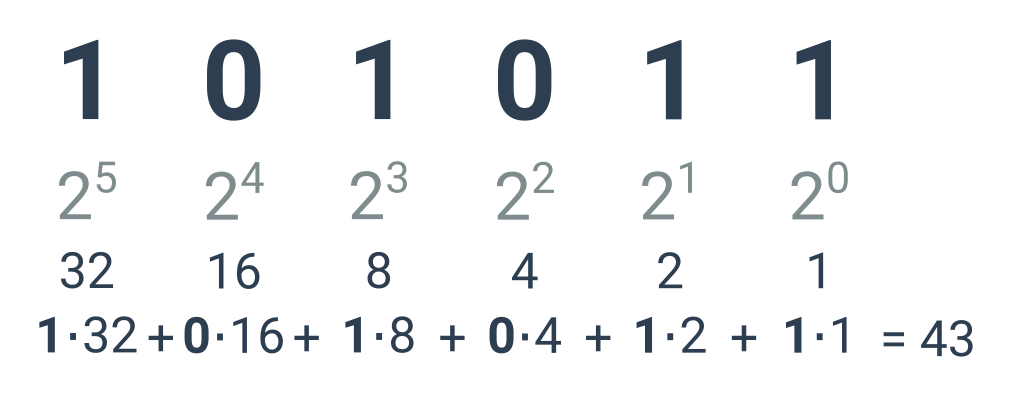
Značení soustav
Abychom odlišili, jestli mluvíme o čísle v binární nebo v desítkové soustavě, přidáváme k číslům dolní indexy značící soustavu. Například číslo 5 v desítkové soustavě budeme psát jako 5_{10}, binární číslo s hodnotou 5 napíšeme jako 101_2. Potom můžeme jasně rozlišit, že například zápisem 11_{10} myslíme desítkové číslo 11, zatímco zápis 11_2 budeme interpretovat jako binární číslo 11 a tedy desítkové číslo 3.
Intuitivní pomůcka
Pro základní představu o binárních číslech můžeme použít pomůcku, kterou máme vždy po ruce – totiž ruku samotnou. Představme si, že si na prsty ruky napíšeme mocniny dvojky:
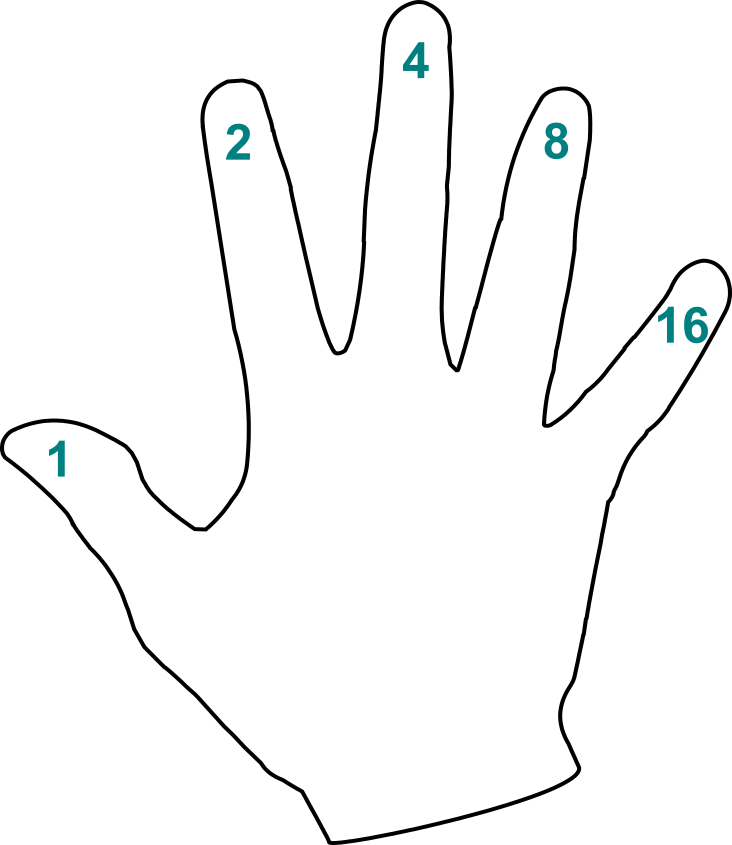
Pak můžeme na prstech jedné ruky počítat nejen do pěti, ale až do třiceti jedné. Každé číslo lze totiž vyjádřit (jednoznačně) jako součet mocnin dvojky. Pokud polohu prstů zaznačíme pomocí nul a jedniček, dostaneme zápis v binární soustavě.
Příklady čísel zapsaných v binární soustavě
| desítkově | součet mocnin | binárně |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 10 |
| 3 | 2+1 | 11 |
| 4 | 4 | 100 |
| 5 | 4+1 | 101 |
| 6 | 4+2 | 110 |
| 7 | 4+2+1 | 111 |
| 8 | 8 | 1000 |
| 9 | 8+1 | 1001 |
| 10 | 8+2 | 1010 |
| 16 | 16 | 10000 |
| 20 | 16+4 | 10100 |
| 30 | 16+8+4+2 | 11110 |
Kromě níže uvedených interaktivních cvičení je k dispozici také pomůcka pro aktivity – kartičky určené k vytištění, rozstříhání a párování (náměty k využití nabízí stránka Aktivity s kartičkami):
Vtip pro zpestření

Bity a bajty
Bit je nejmenší jednotka informace. Může mít pouze dvě různé hodnoty, 0 nebo 1. Bity se sdružují do bajtů (často psáno anglicky jako byte), jeden bajt se skládá z 8 bitů. Bit značíme malým b, bajt velkým B.
Proč zrovna 8 bitů?
Bajt je nejmenší jednotka dat, se kterou počítač operuje. Neexistuje fundamentální důvod, proč by tato jednotka měla být právě 8 bitů, kromě toho, že je to „tak akorát“. Do příliš malého bajtu by se nevešel ani jeden znak abecedy, příliš velký bajt by vedl k plýtvání pamětí.
V počátcích pracovaly různé počítače s různě velkými bajty (např. 7 bitů, 10 bitů), ale časem se 8 bitů stalo standardem. Moct se spolehnout na jednotnou velikost bajtu je totiž extrémně výhodné, například aby jeden program mohl bez potíží fungovat na různých počítačích.
Násobné jednotky
Pro označení velkého množství bajtů se používají násobné jednotky. Například 1 kB = 1000 B a 1 MB = 1 000 000 B. Procvičit si je můžete v tématu Informace, velikost dat.
Bity v binárních číslech
Název „bit“ vznikl složením anglických slov binary digit (česky „dvojková číslice“). Při zápisu čísel ve dvojkové soustavě totiž každá číslice odpovídá jednomu bitu. Například číslo 1100_2 má 4 bity. Nejlevější bit se označuje jako nejvyšší či nejvýznamnější, protože má největší váhu (2^{N-1}, kde N je počet bitů). Naopak nejpravější bit se někdy označuje jako nejnižší či nejméně významný, protože má nejmenší váhu (2^0 = 1).
Kolik bitů potřebujeme?
Pomocí 1 bitu lze rozlišit jen 2 hodnoty (např. zapnuto/vypnuto). S každým dalším bitem se však počet možných hodnot zdvojnásobí. Takže pomocí 2 bitů rozlišíme 4 hodnoty (např. světové strany), pomocí 3 bitů až 8 hodnot (např. den v týdnu) a pomocí 4 bitů až 16 hodnot (např. měsíc v roce). Obecně platí, že, pomocí N bitů lze rozlišit 2^N různých hodnot. Například v 8 bitech (1 bajtu) lze uložit 2^8 = 256 různých hodnot.
Rozsahy hodnot
Pokud ukládáme celá nezáporná čísla pomocí 4 bitů, pak bude nejnižší hodnota 0000_2 = 0 a nejvyšší hodnota 1111_2 = 2^4 - 1 = 16 - 1 = 15. Obecně pro N bitů bude nejvyšší hodnota 111...1_2 = 2^N - 1.
| Bitů | Hodnot | Rozsah |
|---|---|---|
| 4 | 2⁴ = 16 | 0–15 |
| 5 | 2⁵ = 32 | 0–31 |
| 6 | 2⁶ = 64 | 0–63 |
| 7 | 2⁷ = 128 | 0–127 |
| 8 | 2⁸ = 256 | 0–255 |
| 16 | 2¹⁶ = 65 536 | 0–65 535 |
Záporná a desetinná binární čísla
V počítači často potřebujeme pracovat se zápornými nebo desetinnými čísly. Protože však počítače používají pouze nuly a jedničky, je potřeba tato čísla nějakým způsobem zapisovat bez použití mínusu nebo desetinné čárky.
Záporná čísla
Existuje více způsobů, jak zapisovat záporná čísla. Obvykle máme daný určitý počet bitů, se kterými můžeme pracovat, často jeden bajt.
V přímém kódu první bit zleva slouží pro uchování znaménka čísla. Obsahuje 0, pokud je číslo kladné, a 1, pokud je záporné. Na ostatních 7 bitů se zapíše absolutní hodnota čísla. Číslo 5_{10} se tedy v jednom bajtu zakóduje jako 0000 0101 a -5_{10} jako 1000 0101.
V inverzním kódu nejprve zapíšeme absolutní hodnotu čísla. Pokud je číslo kladné, dál neděláme nic. Pokud je záporné, obrátíme hodnotu všech bitů (vyměníme 0 za 1 a naopak). Číslo 5_{10} se tedy v jednom bajtu napíše jako 0000 0101 a -5_{10} jako 1111 1010.
Kódování v doplňkovém kódu (dvojkovém doplňku) začíná podobně jako v inverzním. Nejprve napíšeme absolutní hodnotu čísla a pokud je číslo kladné, dál nepokračujeme. Pro záporná čísla provedeme obrácení (inverzi) bitů a následně ještě přičteme jedničku. Číslo 5_{10} tedy v jednom bajtu zapíšeme jako 0000 0101 a -5_{10} jako 1111 1010 + 1 = 1111 1011. Pokud chceme získat hodnotu záporného čísla nebo obrátit znaménko zpět do plusu, provedeme ten samý sled operací. Nejprve obrátíme všechny bity a poté přičteme 1. Pro číslo -5_{10} by to vypadalo následovně: inverze bitů: 1111 1011 → 0000 0100, přičtení jedničky: 0000 0100 + 1 = 0000 0101. Získali jsme číslo 5_{10}.
Ve všech třech kódech poznáme záporné číslo podle toho, že má na prvním místě zleva 1. Kladná čísla na této pozici vždy obsahují 0.
Desetinná čísla
Desetinná čísla mohou být velmi dlouhá, občas mají dokonce nekonečný zápis. Počítače však mají omezený prostor v paměti, proto se i desetinná čísla ukládají na omezený počet bitů. Tento způsob reprezentace se nazývá zápis s plovoucí desetinnou čárkou a kvůli zmenšenému prostoru může být občas trochu nepřesný.
V zápisu s plovoucí desetinnou čárkou se číslo ukládá pomocí dvou hodnot: mantisy a exponentu. Ve speciálním bitu se navíc uchovává znaménko čísla, pro kladná se uloží 0 a pro záporná 1.
Mantisa představuje základ čísla – v podstatě jsou to číslice použité v zápisu. Desetinná čárka se v mantise nachází vždy na předem dohodnuté pozici, často například za první číslicí zleva. Čím větší prostor (počet bitů) máme na mantisu, tím přesněji můžeme číslo uložit.
Exponent je počet míst, o které se má desetinná čárka v mantise posunout, abychom dostali původní číslo. Kladný exponent znamená posun směrem doprava, čímž se číslo zvětšuje. Záporný exponent značí posun desetinné čárky doleva, tím se číslo víc přibližuje nule. Čím víc místa máme na exponent, tím větší rozsah hodnot můžeme ukládat.
Například číslo 1101{,}001_2 bude mít mantisu 1{,}101 001_2 a exponent 3_{10}. Ve znaménkovém bitu bude 0.
Na obrázku je příklad, jak může být jedno číslo uloženo v paměti počítače na 32 bitech (4 bajtech).

Počítání v binární soustavě
Pokud zvládáme základní princip binární soustavy, můžeme se pustit do aritmetických operací.
Sčítání binárních čísel
Binární čísla můžeme sčítat pod sebou velmi podobně, jako jsme zvyklí sčítat čísla v desítkové soustavě. Jediný rozdíl nastává, pokud sčítáme dvě jedničky. Protože 1_2 + 1_2 = 10_2, v takovém případě zapíšeme 0 a přenášíme 1 do vyššího řádu.
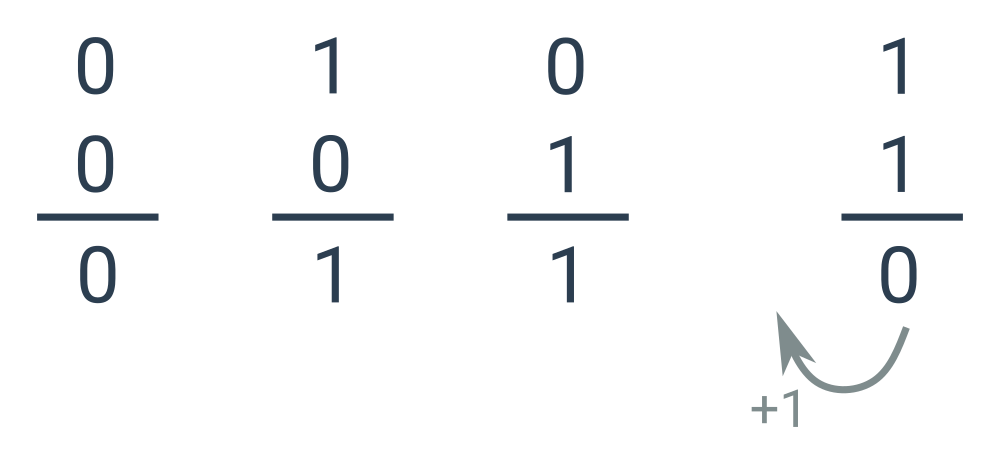
Odčítání binárních čísel
Odčítání binárních čísel funguje obdobně. K přenosu dochází pouze při počítání rozdílu 0_2 - 1. V takovém případě si „vypůjčíme“ jedničku z vyššího řádu – jako bychom počítali 10_2 - 1_2. Potom zapíšeme 1 a v dalším řádu navíc odečteme jedničku, kterou jsme si půjčili.
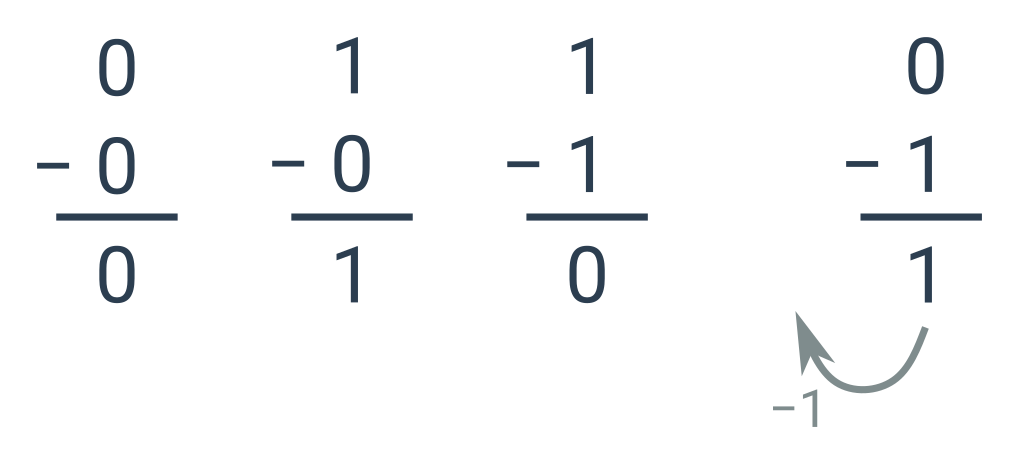
Násobení binárních čísel
Násobení binárních čísel je také téměř stejné jako u desítkových čísel. Násobíme tak, jako kdybychom měli dvě desítková čísla složená pouze z nul a jedniček. Sčítání řádků vzniklých násobením potom probíhá jako binární sčítání, které je popsáno výše.
Pokud máme binární číslo násobit mocninou dvojky, můžeme si práci velmi ulehčit. Stačí pouze přidat na konec čísla tolik nul, kolikátou mocninou dvojky násobíme. Například při násobení dvěma přidáváme 1 nulu (2 = 2^1), při násobení osmi přidáváme 3 nuly (8 = 2^3). Celočíselné dělení mocninou dvojky je také jednoduché, stačí odstranit tolik posledních číslic z dělence, kolikátou mocninou dvojky dělíme.
NahoruBitové operace
Bitové operace spojují logiku s binárním zápisem čísel. Provádějí logické úkony přímo nad jednotlivými bity binárních čísel, podle čehož také dostaly svůj název. Na rozdíl od běžné aritmetiky zde neexistuje žádný „přenos do vyššího řádu“ (carry). Každá pozice v čísle se zpracovává izolovaně. Bitové operace se vyznačují také tím, že nepracují jen s jedním bitem, ale s celou posloupností bitů najednou.
Logické operace
Logické operace jsou typickou ukázkou bitových operací. Mezi nejčastěji používané patří bitová negace (NOT), konjunkce neboli součin (AND), disjunkce neboli součet (OR) a neekvivalence (XOR). Více se logickým spojkám věnuje sekce logiky.
Příklady logických operací
Unární bitová operace NOT vezme jeden binární řetězec a kažou hodnotu v něm změní na opačonu; tedy z každé 0 udělá 1 a z každé 1 udělá 0.
- Z řetězce 10100 udělá řetězec 01011.
- Z řetězce 11111 udělá řetězec 00000.
- Z řetězce 00000 udělá řetězec 11111.
Binární bitové operace vezmou dva řetězce stejné délky a zkombinují je do jednoho nového řetězce bit po bitu:
- Operace AND udělá z řetězců 11010 a 01110 řetězec 01010
- Operace AND udělá z řetězců 11110 a 00110 řetězec 00110
- Operace OR udělá z řetězců 10010 a 00011 řetězec 10011
- Operace OR udělá z řetězců 11110 a 00111 řetězec 11111
- Operace XOR udělá z řetězců 10010 a 00011 řetězec 10001
- Operace XOR udělá z řetězců 11110 a 00111 řetězec 11001
Posuny
Dalším častým druhem operací jsou posuny. Posun, neboli shift, se převádí přidáním nuly na začátek, případně na konec, sekvence bitů a odebráním jednoho bitu z druhé strany řetězce. Posun doprava (>>) tedy přidá nulu na začátek a odebere poslední bit, což pro binární čísla odpovídá celočíselnému dělení dvěma. Posun doleva (<<) naopak přidá nulu na konec řetězce a odebere první bit, což pro binární čísla odpovídá násobení dvěma.
Příklady posunů
Posun doprava (>>) o 1 pozici celočíselně dělí dvěma. Posun o 2 pozice dělí čtyřmi, posun o 3 dělí osmi a tak dále.
- Z čísla 10 udělá číslo 5: 1010 >> 1 = 0101
- Z čísla 4 udělá číslo 2: 0100 >> 1 = 0010
- Z čísla 7 udělá číslo 3: 0111 >> 1 = 0011
- Posun o 2 udělá z čísla 10 číslo 2: 1010 >> 2 = 0010
- Posun o 2 udělá z čísla 7 číslo 1: 0111 >> 2 = 0001
- Posun o 3 udělá z čísla 10 číslo 1: 1010 >> 3 = 0001
Posun doleva (<<) o 1 pozici celočíselně násobí dvěma. Posun o 2 pozice násobí čtyřmi, posun o 3 násobí osmi a tak dále.
- Z čísla 5 udělá číslo 10: 0101 << 1 = 1010
- Z čísla 4 udělá číslo 8: 0100 << 1 = 1000
- Z čísla 7 udělá číslo 14: 0111 << 1 = 1110
- Posun o 2 udělá z čísla 1 číslo 4: 0001 << 2 = 0100
- Posun o 2 udělá z čísla 3 číslo 12: 0011 << 2 = 1100
- Posun o 3 udělá z čísla 1 číslo 8: 0001 << 3 = 1000
Využití
Díky izolovanosti provádění operace na každém bitu zvlášť je v počítači často možné provádět více bitových operací paralelně. Následkem toho je práce s bitovými operacemi velmi rychlá, rychlejší než například sčítání nebo odčítání.
Bitové operace je možné používat na libovolné binární řetězce, nejen na čísla. Například do osmi bitů se dá místo osmibitového čísla uložit 8 indikátorů, takzvaných flagů, nesoucích binární informaci (s hodnotami true nebo false). S těmito flagy je pak možné manipulovat zároveň pomocí binárních operací.
NahoruHexadecimální čísla
Hexadecimální čísla jsou čísla zapsaná v šestnáctkové (hexadecimální) soustavě. Tato soustava využívá 16 symbolů (0–9 a A–F, kde A–F představují desítku až patnáctku).

Hexadecimální čísla jsou úzce propojena s binární soustavou. Každý symbol v šestnáctkové soustavě představuje čtyři bity v binární soustavě, což usnadňuje převody mezi těmito soustavami. Každé číslo v hexadecimální soustavě lze převést na binární tím, že každému hexadecimálnímu symbolu přiřadíme čtyři bity.

Příklady převodu čísel
- Hexadecimální číslo 1A odpovídá binárnímu číslu 00011010, protože 1 = 0001 a A = 10 = 1010. V desítkové soustavě odpovídá 1A číslu 26 (1 \cdot 16 + 10).
- Desítkové číslo 255 může být vyjádřeno hexadecimálně jako FF, kde F značí patnáctku.
Příklady čísel zapsaných v desítkové, binární a šestnáctkové soustavě
| desítkově | součet mocnin dvojky | binárně | součet mocnin šestnáctky | šestnáctkově |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 10 | 2 | 2 |
| 3 | 2+1 | 11 | 3 | 3 |
| 4 | 4 | 100 | 4 | 4 |
| 5 | 4+1 | 101 | 5 | 5 |
| 6 | 4+2 | 110 | 6 | 6 |
| 7 | 4+2+1 | 111 | 7 | 7 |
| 8 | 8 | 1000 | 8 | 8 |
| 9 | 8+1 | 1001 | 9 | 9 |
| 10 | 8+2 | 1010 | 10 | A |
| 16 | 16 | 10000 | 16 + 0 | 10 |
| 20 | 16+4 | 10100 | 16 + 4 | 14 |
| 26 | 16+8+2 | 11010 | 16 + 10 | 1A |
| 30 | 16+8+4+2 | 11110 | 16 + 14 | 1E |
| 32 | 32 | 100000 | 2×16 + 0 | 20 |
| 160 | 128+32 | 10100000 | 10×16 + 0 | A0 |
| 240 | 128+64+32+16 | 11110000 | 15×16 + 0 | F0 |
| 255 | 128+64+32+16+8+4+2+1 | 11111111 | 15×16 + 15 | FF |
Hexadecimální čísla jsou často využívána v oblasti barevného zobrazení, například v RGB modelu. Každá složka barvy (červená, zelená, modrá) je vyjádřena osmi bity, což odpovídá dvěma hexadecimálním číslicím. Například barva červená s plnou intenzitou by byla zapsána jako #FF0000, kde FF reprezentuje maximální hodnotu červené složky.
Příklady zápisů RGB barev
Desítkový zápis se typicky zapisuje jako trojice, šestnáctkový začíná symbolem #.
| barva | desítkově trojicí | šestnáctkově |
|---|---|---|
| bílá | (255, 255, 255) | #FFFFFF |
| černá | (0,0,0) | #000000 |
| červená | (255,0,0) | #FF0000 |
| zelená | (0,255,0) | #00FF00 |
| modrá | (0,0,255) | #0000FF |
| žlutá | (255,255,0) | #FFFF00 |
| oranžová | (255,165,0) | #FFA500 |
| hnědá | (165,42,42) | #A52A2A |
| růžová | (255,192,203) | #FFC0CB |
| fialová | (128,0,128) | #800080 |
| šedá | (128,128,128) | #808080 |
Přenos a komprese dat
Počítače často využíváme k tomu, abychom si ukládali informace a posílali je ostatním. Dejme tomu, že třeba vyfotíte fotku a chcete ji poslat kamarádovi.
Fotka je uložená na počítači jako posloupnost nul a jedniček. Kolik těch nul a jedniček je potřeba? To nám říká velikost dat, kterou měříme v bajtech a jejich násobcích (megabajty, gigabajty). Velikosti dat se hodí rozumět, abychom třeba měli jasno v tom, kolik fotek se nám vleze na paměťovou kartu.
Pokud vyfotíme fotky s vysokým rozlišením, velikost souboru bude velká a do paměti se nám jich vejde málo. Možná bychom si raději uložili fotek víc, byť budou trochu méně kvalitní. K tomu slouží komprese dat.
A když vybranou fotku posíláme kamarádovi, dochází k přenosu dat. Nuly a jedničky, které reprezentují naši fotku, při přenosu mohou putovat vzduchem nebo optickými kabely. Při tom putování se může stát, že se něco pokazí. Přenos dat tedy potřebujeme udělat chytře, aby bylo možné chyby najít a opravit.
NahoruInformace, velikost dat
Jeden z hlavních účelů počítačů je práce s informacemi a daty. Informace můžeme ukládat, přenášet mezi počítači a upravovat je. Aby počítače mohly s informacemi pracovat, musíme je zakódovat, tedy zaznamenat je určitým ustáleným způsobem, kterému budou počítače rozumět. V počítači se všechna data kódují pomocí nul a jedniček.
Bit je základní a nejmenší jednotka informace. Může mít dvě různé hodnoty, 0 nebo 1. Bity se sdružují do bajtů (často psáno anglicky jako byte), jeden bajt se skládá z 8 bitů. Počítače obvykle pracují s celými bajty, bajt je tedy většinou nejmenší jednotka, se kterou počítač dokáže manipulovat. Proto i velikost počítačové paměti a souborů v ní uložených se udává v bajtech. Bit se značí jako b, bajt jako B.
Všechna data jsou v počítačích ukládána a zpracovávána jako řady bajtů. Protože se soubory v počítačích často skládají z mnoha milionů bajtů, pro jednodušší značení velikosti dat používáme násobné jednotky. Pro jednodušší převádění mezi jednotkami zde používáme vztah 1 kB = 1000 B, někdy se však můžeme setkat i se vztahem 1 kB = 1024 B = 2^{10} B. Stejně to platí i pro ostatní násobné jednotky, tedy někdy můžeme vidět 1 MB = 1024 kB, 1 GB = 1024 MB atd.
| značka | název | velikost |
|---|---|---|
| kB | kilobajt | 1000 B |
| MB | megabajt | 1000 kB |
| GB | gigabajt | 1000 MB |
| TB | terabajt | 1000 GB |
| PB | petabajt | 1000 TB |
Převody platí i v případech, kdy jsou tyto jednotky kombinované s jinými, například jako bit/s.
Příklad kombinovaných jednotek
| značka | název | velikost |
|---|---|---|
| b/s, bit/s, bps | bit za sekundu | 0,125 B/s |
| kb/s, kbit/s | bit za sekundu | 1000 b/s |
| Mb/s, kbit/s | bit za sekundu | 1000 kb/s |
| Gb/s, kbit/s | bit za sekundu | 1000 Mb/s |
| B/s | bajt za sekundu | 8 b/s |
| kB/s | kilobajt za sekundu | 1000 B/s |
| MB/s | megabajt za sekundu | 1000 kB/s |
| GB/s | gigabajt za sekundu | 1000 MB/s |
| TB/s | terabajt za sekundu | 1000 GB/s |
Příklady velikostí objektů v počítači
| velikost | objekt |
|---|---|
| několik B | 1 písmeno anglické abecedy |
| několik kB | krátký e-mail bez obrázků |
| několik desítek kB | několikastránkový textový dokument bez obrázků |
| několik set kB | obrázek ve špatné kvalitě |
| několik MB | knížka v pdf, prezentace s pár obrázky |
| několik GB | film |
| několik TB | pevný disk |
| několik PB | datové centrum |
Komprese dat
Komprese je proces, kterým můžeme výrazně zmenšit prostor, který naše data zabírají v paměti, a přitom zachovat jejich obsah relativně nezměněný. Používáme ji, když chceme ušetřit místo v paměti nebo když potřebujeme data někam poslat. Když na soubor aplikujeme kompresi, komprimujeme ho, když chceme zpět získat původní obsah, dekomprimujeme ho.
Bezztrátová komprese zachovává všechny informace obsažené v souboru, nepřijdeme tak o žádná data a můžeme se kdykoli vrátit k původní verzi souboru. Její nevýhodou je, že nedokáže zmenšovat velikost tak dobře jako ztrátová. Velmi obvykle se používá pro texty a pro komprimaci souborů nezávisle na jejich formátu. Využívají ji například archivy ZIP a RAR, které dokáží zkomprimovat několik různých souborů nebo složek najednou. Některé další formáty s bezztrátovou kompresí jsou PNG, GIF (obraz) a FLAC (video).
Jedním z jednoduchých algoritmů pro bezztrátovou kompresi je RLE (run-length encoding). Řadu po sobě jdoucích stejných znaků zakóduje do dvojice (počet hodnot, hodnota). Například řetězec aaaaaa zakóduje jako 6a, řetězec cccddce jako 3c2d1c1e.
Ztrátová komprese je efektivnější ve zmenšování velikosti souborů. Při komprimaci však můžeme navždy přijít o nějaké informace, které byly v původním souboru. Zkomprimovaný soubor tak může obsahovat lehce zkreslené detaily nebo mít nižší kvalitu než originál. Hojně se používá pro obrázky, video a zvuk. Formáty využívající ztrátovou kompresi jsou například JPG (obraz), MP3 (zvuk), MP4 a OGG (video).
NahoruPřenos dat
Informace jsou v počítači vždy nějak zakódované, tedy zaznamenané určitým ustáleným způsobem. Zakódování stejné informace pro různé účely (uložení, přenos, zobrazení) může vypadat úplně jinak. Informace se kódují do datového proudu, tedy do řady bajtů, se kterou počítač může pracovat.
V současnosti neustále probíhá přenos dat mezi počítači, z velké části po internetu, avšak i jinými způsoby. Přenos mezi příjemcem a odesílatelem probíhá přes komunikační kanál, což je většinou skupina více různých prostředků (softwarových, hardwarových, …), které spolupracují, aby přenos dat mohl fungovat.
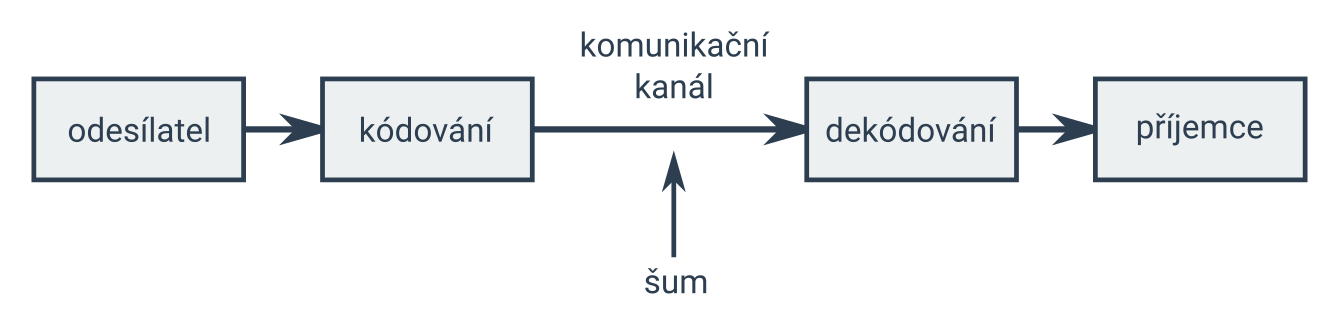
Přenosová rychlost je jednotka, která měří množství dat přenesených za určitou jednotku času. Základní jednotka je b/s (bit za sekundu), někdy také bps (bit per second). Používá se i B/s (bajt za sekundu) a násobné jednotky jako kb/s, Mb/s apod.
Chyby při přenosu
V komunikačním kanálu na zprávy působí šum, který může data poškodit — na některém místě v datovém proudu se místo 0 objeví 1 nebo naopak. Proto často využíváme redundance — posíláme spolu se zprávou nějakou další informaci, která nám pomůže odhalit chybu, nebo ji rovnou opravit. Příklady redundancí jsou:
- Kontrolní součet je číslo nebo řetězec, který pošleme spolu se zprávou. Jednoduchá metoda kontrolního součtu je sečíst hodnoty všech bajtů, často se však používají i mnohem složitější funkce.
- Do paritního bitu uložíme 1, pokud je počet 1 v daném úseku dat lichý a 0, pokud je počet 1 sudý.
- Kontrolním číslem doplníme zprávu tak, aby celý datový proud měl určitou vlastnost, např. aby součet hodnot všech bajtů byl dělitelný určitým číslem.
- Poslání celé zprávy třikrát nám sice umožňuje chyby rovnou opravovat, posíláme však trojnásobný objem dat.
U přijaté zprávy zkontrolujeme, jestli redundance stále sedí (např. znovu spočítáme kontrolní součet a porovnáme s obdrženým). Pokud něco není v pořádku, můžeme zkusit chybu opravit, případně požádat odesílatele o opětovné poslání.
Signál
Data jsou přenášena pomocí signálu, který má dva druhy.
Analogový signál je spojitý a mnohem citlivější vůči šumu. Může nabývat nekonečně mnoha hodnot. V současnosti už se pro přenos dat nepoužívá tolik často. Aby s analogovým signálem mohly pracovat počítače, je nejprve potřeba ho převést na digitální.
Digitální signál je nespojitý a nabývá omezeného počtu hodnot, v informatice to jsou typicky 0 a 1. Nyní je hojně využíván pro přenos dat mezi počítači.
Na obrázku je analogový signál znázorněn oranžovou linkou a digitální pomocí modrých bodů.

Modelování pomocí grafů
Pojem „graf“ má bohužel v češtině několik odlišných významů. Mimo jiné používáme grafy funkcí, grafy pro vizualizaci dat a grafy modelující vztahy mezi objekty.
Zde se zabýváme posledním zmíněným významem. V tomto případě se grafem rozumí vrcholy („tečky“) a hrany („spojnice“). Takovéto grafy se používají pro modelování vztahů mezi objekty, například:
- Dopravní síť: vrcholy jsou města, hrany jsou silnice mezi nimi.
- Sociální síť: vrcholy jsou lidé, hrany odpovídají přátelství.
- Webové stránky: vrcholy jsou jednotlivé stránky, hrany odpovídají odkazům mezi nimi.
Základní témata o grafech se zaměřují na použití grafů na intuitivní úrovni (tato témata jsou vhodná i na úrovni základní školy):
- Grafy a abstrakce – použití grafu jako modelu skutečnosti, porozumění významu grafů
- Grafy sousednosti – jeden konkrétní případ užití grafů, na kterém se dá čistě obrázkovou formou dobře procvičit princip abstrakce
- Nejkratší cesty – intuitivní příklady na hledání nejkratších cest mezi vrcholy, což je jedna z typických aplikací grafů
- Izomorfní grafy – téma se složitě znějícím názvem, ale poměrně intuitivními obrázkovými zadáními; hledáme grafy, které mají „stejná spojení“
Grafy mají v informatice bohaté využití. Abychom mohli s grafy více pracovat, nevystačíme jen s obrázky, ale potřebujeme i přesně pracovat s pojmy. Tím se zabývá oblast zvaná teorie grafů. Toto důkladnější pojetí už je na úrovni střední a vysoké školy:
NahoruGrafy a abstrakce
Při řešení složitějšího nebo nepřehledného problému je často dobrý nápad si ho nakreslit. Grafy umožňují jednoduše graficky znázornit situaci s různými objekty, které mezi sebou mají vztahy. Grafy se skládají z vrcholů a hran, které propojují vrcholy mezi sebou. Vrcholy se obvykle zobrazují jako puntíky nebo kroužky, hrany kreslíme jako čáry nebo šipky. K vrcholům i hranám můžeme přidávat různé popisky, pokud se nám to hodí. Vrcholy modelují objekty, zatímco hrany představují vztahy mezi nimi.
Některými příklady modelování pomocí grafů jsou:
| Případ | Vrcholy | Hrany |
|---|---|---|
| mapa | místa | cesty mezi místy |
| sociální síť | lidé | kdo koho sleduje |
| potravní síť | živočichové | kdo se kým živí |
| síť hromadné dopravy | zastávky nebo přestupní stanice | trasy |
Grafy umožňují zachovat důležité informace o skutečnosti a přitom vynechat ty, které pro nás nejsou užitečné. Například, pro nalezení nejkratší cesty mezi vesnicemi nepotřebujeme vědět, jestli je v okolí nějaký rybník nebo les.
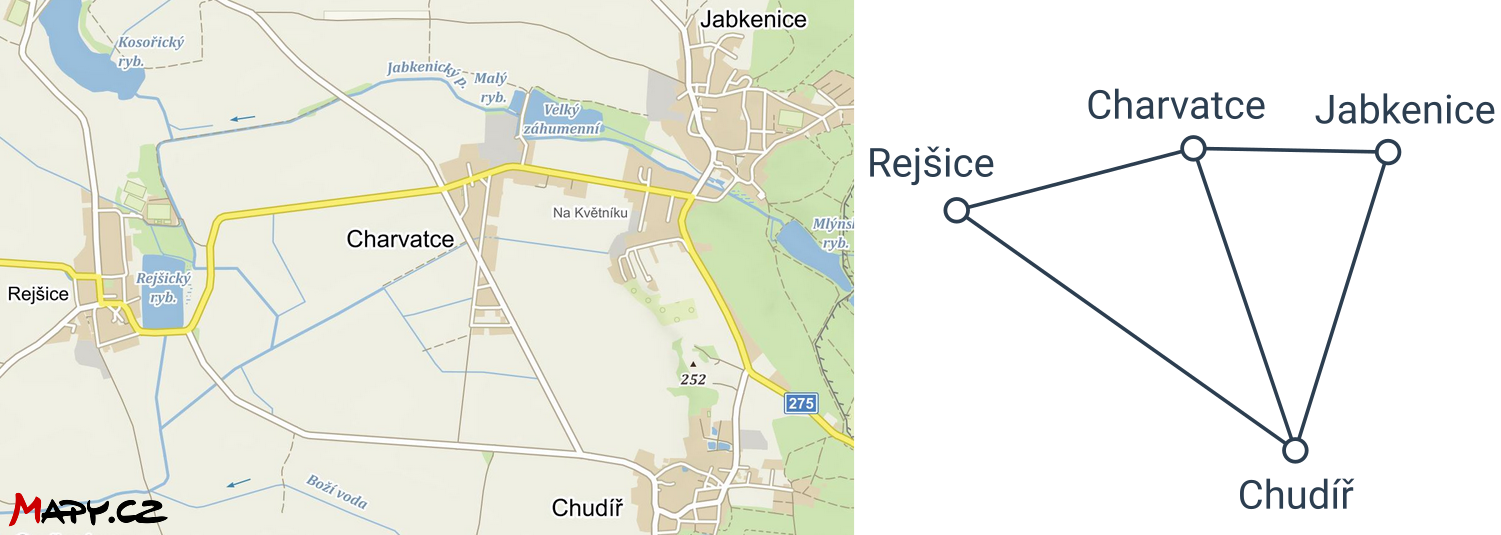
Příklad: mapa
Jednotlivá místa na mapě jsou modelovány jako vrcholy, cestám mezi nimi odpovídají hrany.
Příklad: sociální síť
Lidé jsou vrcholy, kdo koho sleduje modelují šipky (hrany).

Grafy: nejkratší cesty
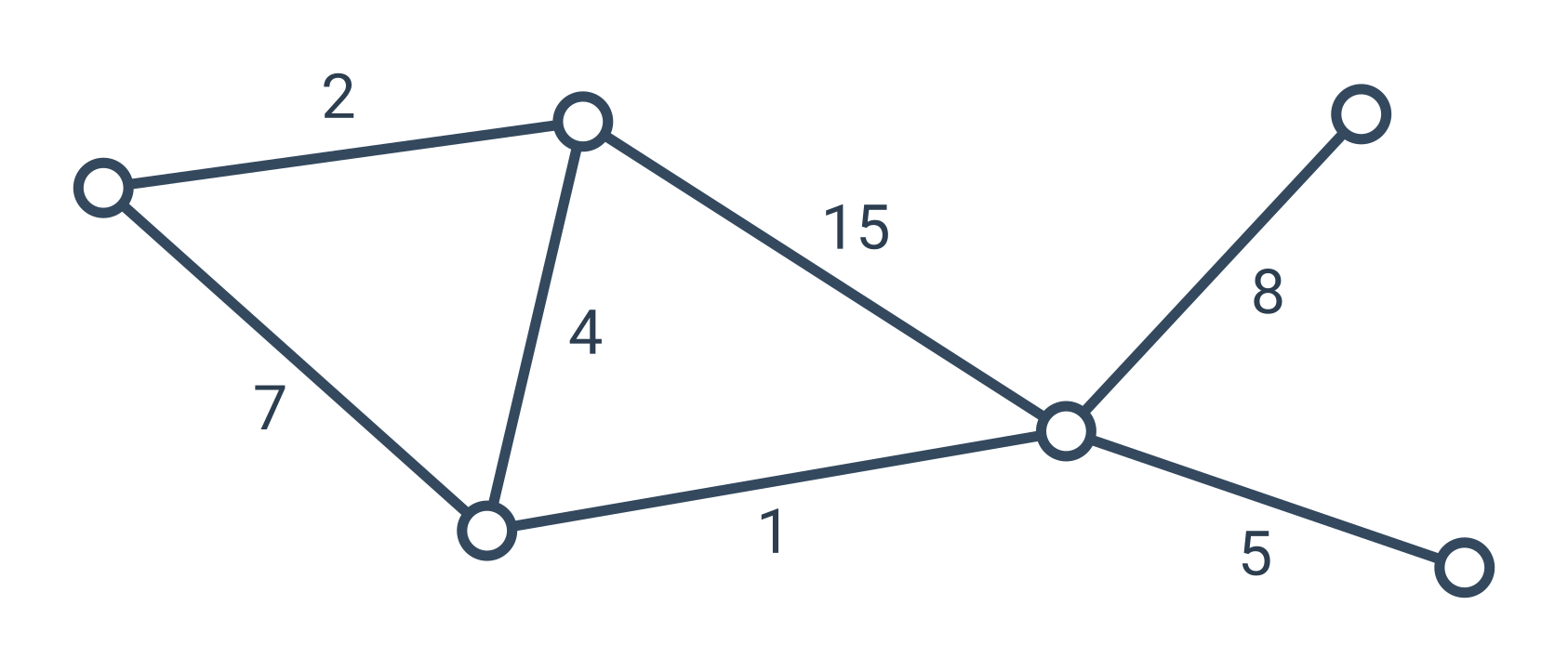
Jednou z typických úloh na grafech je hledání cest mezi vrcholy. Pokud chceme v mapě najít co nejkratší cestu z jednoho místa do jiného, můžeme mapu převést na graf, v němž budeme hledat nejkratší cestu po hranách. V takové situaci se často hodí k hranám (cestám mezi místy) doplnit údaje o jejich délce.
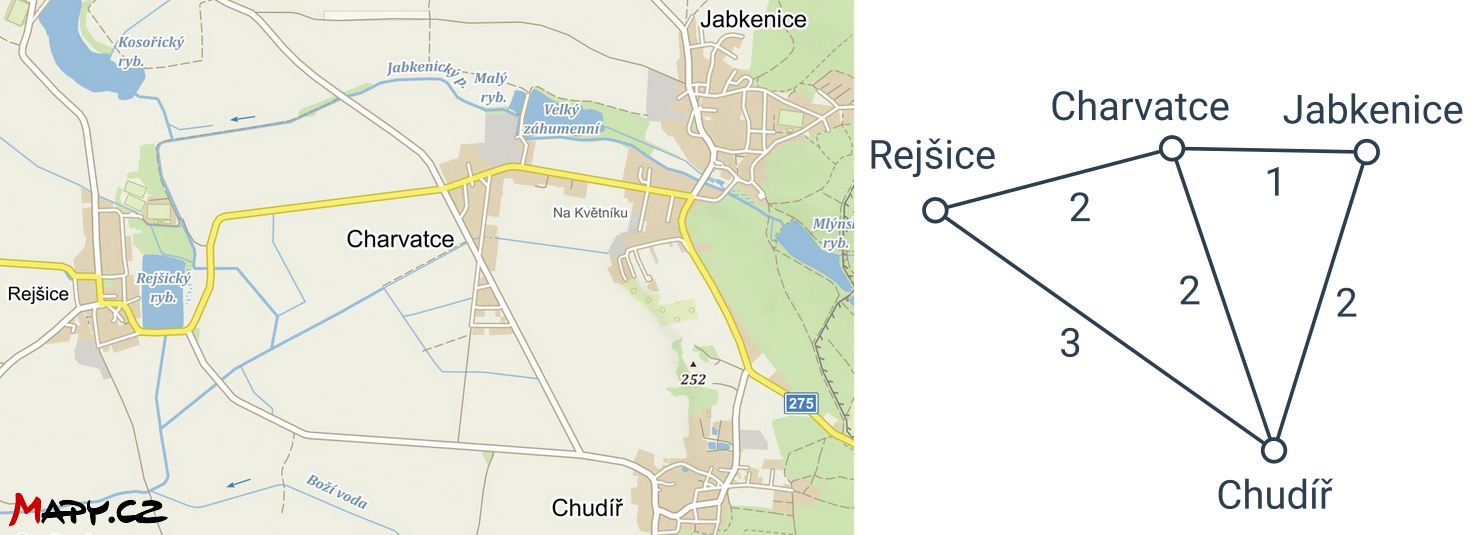
Z tohoto grafu bychom například zjistili, že nejkratší cesta z Rejšic do Jabkenic má 3 kilometry a vede přes Charvatce.
Cesty je možné kromě prostorové vzdálenosti porovnávat i podle jiných kritérií:
- Když internetový poskytovatel zajišťuje propojení svých sítí, může případná spojení porovnávat podle ceny za jejich pronájem.
- Navigace neporovnává cesty jen podle délky, ale i podle času dojezdu. Cesta po dálnici pravděpodobně bude o mnoho rychlejší, než stejně dlouhá cesta po okresní silnici.
Shodné grafy
Grafy jsou izomorfní, pokud mají stejný počet vrcholů a „stejná spojení“. Zde nebudeme rozebírat přesnou matematickou definici (tu najdete třeba zde), ale jen intuitivní představu. Představme si vrcholy grafu jako dřevěné kolíčky a hrany jako gumičky mezi nimi. S kolíčky a gumičkami můžeme hýbat a pořád je to „stejný graf“, protože vztah spojení zůstává zachován. Izomorfismus grafů se týká právě tohoto typu „stejnosti“. Můžeme s jedním grafem hýbat tak, až z něj dostaneme ten druhý?
Cvičení na izomorfní grafy nejsou užitečná ani tak kvůli pojmu samotnému, ale především jako trénink abstrakce. Při hledání izomorfních grafů musíme odhlédnout od detailů (jak přesně jsou hrany zakresleny) a soustředit se pouze na důležité vztahy (kdo je s kým spojen).
NahoruTeorie grafů: základní pojmy
Graf je struktura, která nám pomáhá znázorňovat objekty a vztahy mezi nimi. Skládá se z vrcholů a hran. Vrcholy často reprezentují reálné objekty a obvykle je kreslíme jako tečky nebo kolečka. Hrany představují vztahy mezi vrcholy, na obrázku obvykle vypadají jako čáry mezi vrcholy. Každá hrana vede mezi dvěma vrcholy, oba její konce tedy musí být připojeny k některému vrcholu.
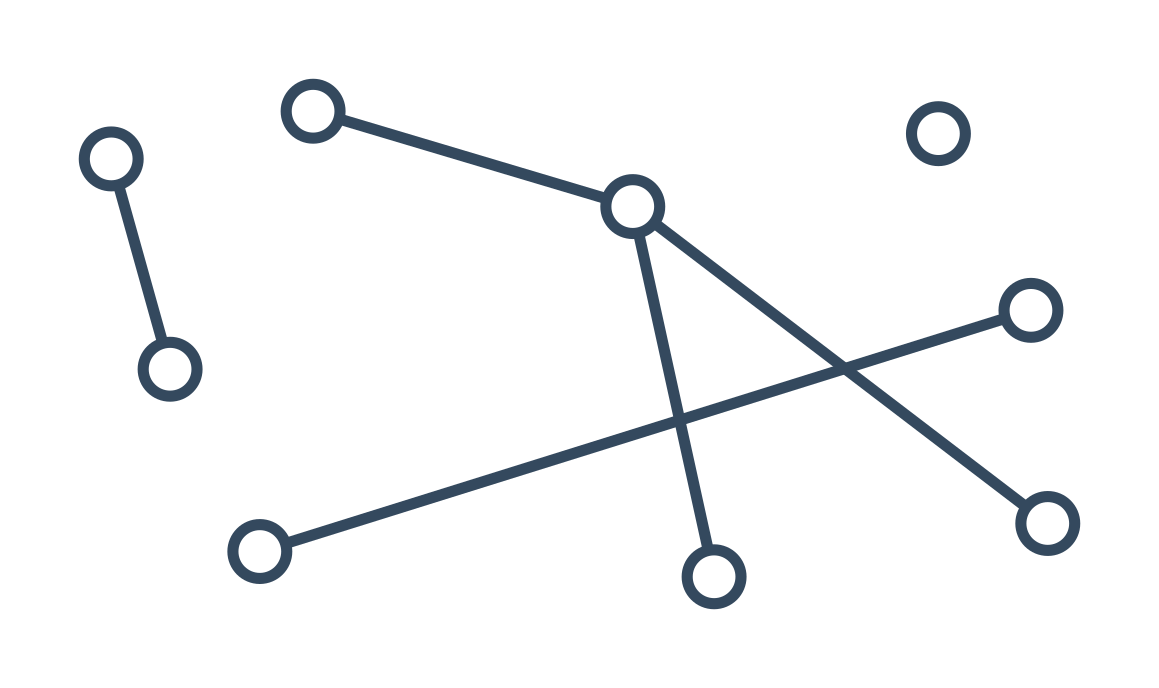
Mezi základní grafové pojmy patří:
- Stupeň vrcholu je počet hran, které z daného vrcholu vychází.
- Cesta mezi dvěma určenými vrcholy existuje, pokud v grafu dokážeme přejít po hranách z jednoho vrcholu do druhého.
- Vzdálenost dvou vrcholů je délka nejkratší cesty mezi těmito vrcholy. Naopak nám vůbec nezáleží na tom, jak daleko jsou od sebe vrcholy na obrázku, pokud graf nakreslíme.
Dále si ukážeme některá rozšíření obyčejných grafů, tedy druhy grafů, jejichž vlastnosti jsou nějakým způsobem upravené.
V orientovaném grafu mají hrany přesně určený směr, kterým vedou, a tedy i začáteční a koncový vrchol. To je rozdíl od grafů, o kterých jsme uvažovali doposud – tam hrany vedou „mezi vrcholy“ a nemají dáno, kde začínají a kde končí. Hrany orientovaných grafů se často znázorňují jako šipky.
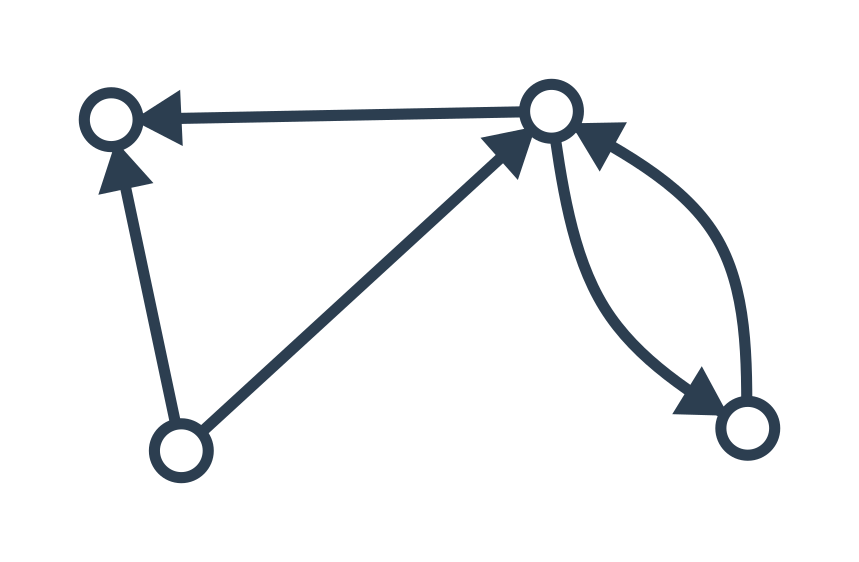
V ohodnoceném grafu má každá hrana přiřazenu určitou hodnotu (nazývanou také váha). Na obrázku píšeme váhy jako čísla ke hranám. Pomocí těchto hodnot můžeme snadno znázornit například délky cest mezi městy.
Teorie grafů: vlastnosti a části grafů
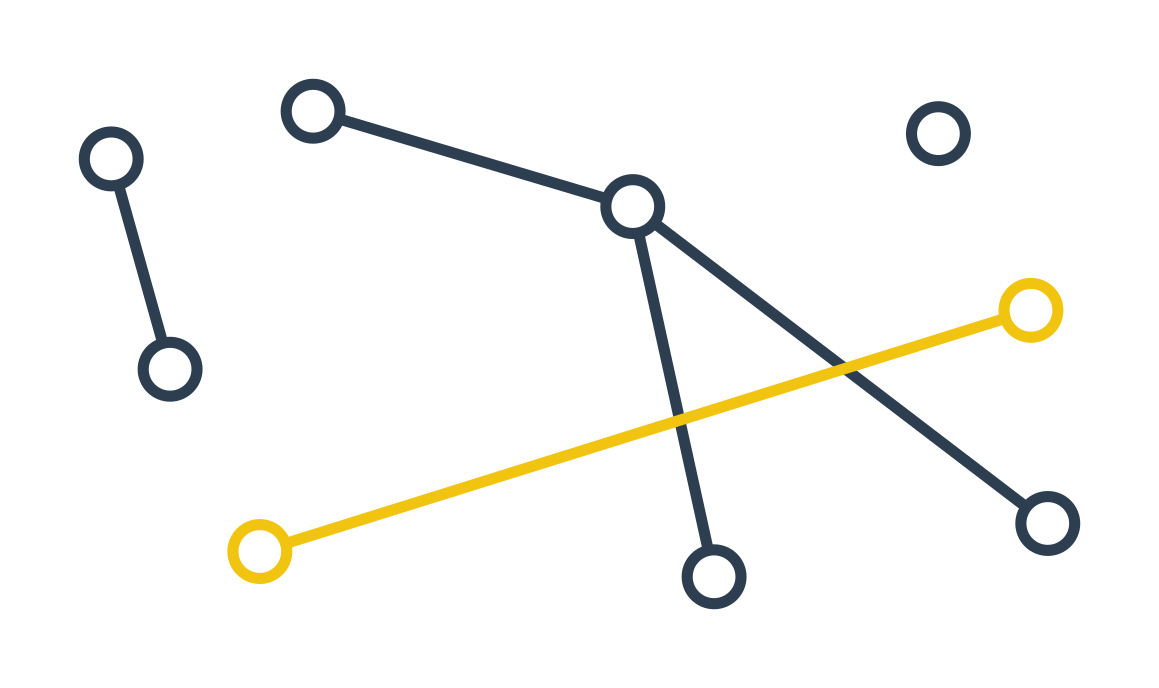
Graf je souvislý, pokud mezi každými dvěma z jeho vrcholů vede cesta. To znamená, že všechny vrcholy jsou spolu nějak propojené – dokážeme v grafu přejít po hranách z každého vrcholu do všech ostatních.
Komponenta souvislosti je část grafu, která je souvislá, ale pokud bychom do ní chtěli zahrnout nějaké další hrany nebo vrcholy, souvislá by být přestala. Každý graf je rozdělený na několik komponent souvislosti. Pokud je graf souvislý, tvoří sám o sobě jednu komponentu souvislosti. Graf na obrázku není souvislý a skládá se ze 4 komponent souvislosti, jedna z nich je vyznačená žlutě.
Podgraf je část (tedy některé vybrané vrcholy a hrany) grafu, která sama o sobě také tvoří graf. Každá hrana v podgrafu tedy musí mít na obou svých koncích vrchol, který také patří do podgrafu. Žluté vrcholy a hrany na obrázku tvoří podgraf.
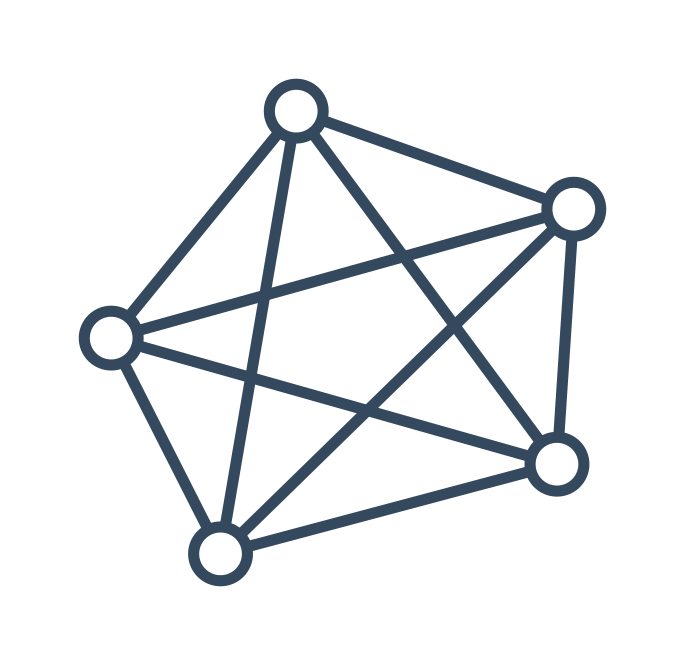
V úplném grafu je každý vrchol je spojený s každým. Tento graf má tedy maximální počet hran, který může mít.
Strom je souvislý graf, který neobsahuje žádnou kružnici (cyklus) jako podgraf. Stromy mají mnoho zajímavých vlastností (např. mezi každými dvěma vrcholy vede právě jedna cesta) a často se v informatice používají (např. pro přehledné a efektivní uložení dat).
Modelování vztahů a systémů
Lidé, věci a další objekty na světě jsou často různými způsoby propojené – navzájem se ovlivňují, souvisí spolu, nebo jsou si třeba nějak podobné. Jinak řečeno, mají mezi sebou vztahy. Víc navzájem propojených objektů tvoří systém. Abychom se ve složitějším systému lépe vyznali, často pomáhá si daný systém znázornit nebo nakreslit – namodelovat.
Pro snadnější proniknutí do tématu dělíme procvičování na několik podtémat:
- Vlastnosti a vztahy – rozlišování mezi vztahy (Alena je dcera Jany. Tomáš je členem fotbalového týmu.) a vlastnostmi (Alena má hnědé oči.)
- Typy vztahů – zobecnění, celek–část, příčina–následek, prerekvizita…
- Entitně-vztahové modely – způsob zakreslení vlastností a vztahů, který se používá mj. při návrhu databází
Vlastnosti a vztahy
Objekty (věci, lidé, skupiny, …) mohou mít vztahy s dalšími objekty. Vztahy vyjadřují, jak spolu různé objekty souvisí.
Pokud o Ondrovi řekneme, že má sestru Anetu, říkáme, že mezi Ondrou a Anetou je vztah – konkrétně sourozenecký. Dále můžeme říct, že Ondra chodí na 2. ZŠ v Dobříši. To je vztah mezi Ondrou a školou, kterou navštěvuje.
Objekty dále mohou mít různé vlastnosti, tedy další informace, které je nějak popisují.
Ondrovy vlastnosti jsou například jeho zelené oči a tmavě hnědé vlasy. Vlastností školy je třeba to, že stojí na adrese Školní 1035.
Při určování, jestli jde o vlastnost, nebo o vztah mezi dvěma objekty, často pomáhá zamyslet se, jestli jedna část vztahu může existovat bez druhé. Pokud je jedna část závislá na existenci druhé, jde pravděpodobně o vlastnost. V opačném případě je to spíše vztah. Obecně, vazba mezi objektem a jeho vlastností je obvykle pevnější než vztah mezi dvěma objekty.
NahoruKdyby 2. ZŠ v Dobříši neexistovala, neexistovala by ani adresa Školní 1035 – protože by na té adrese nestála žádná budova. Proto je adresa vlastností školy. Naproti tomu, pokud by neexistovala 2. ZŠ, Ondra by mohl jednoduše chodit na jinou školu. Zároveň, kdyby Ondra bydlel v jiném městě a nechodil na 2. ZŠ, ta by i přesto mohla stát v Dobříši a vzdělávat jiné děti. Proto věta „Ondra chodí na 2. ZŠ“ vyjadřuje vztah a nikoli vlastnost.
Typy vztahů
Vztahy mezi objekty nejsou všechny stejné. Když určíme, jakého typu jednotlivé vztahy jsou, pomůže nám to systém lépe pochopit a komunikovat o něm. Určení vztahů je klíčové, pokud potřebujeme systém zachytit programem či databází – různé typy vztahů se totiž v takovém případě implementují různými způsoby. Existuje mnoho typů vztahů, mezi ty nejběžnější patří:
Generalizace (zobecnění)
Jedna entita je typem jiné, obecnější entity. Jablko je typem ovoce, tj. ovoce je generalizací (zobecněním) jablka. V opačném směru (od obecnějšího ke konkrétnějšímu) mluvíme o specializaci (jablko je specializací ovoce), případně o konkrétním příkladu neboli instanci (3 + 4 je příkladem (instancí) obecného konceptu sčítání.) V kontextu jazyka se pro generalizaci a specializaci používá označení slova nadřazená a podřazená.
Kompozice a agregace (celek–část)
Kompozice i agregace označují vztah mezi celkem a jeho částí. O kompozici mluvíme tehdy, pokud jsou části s celkem neoddělitelně spjaty a když celek zanikne, zaniknou i jeho části (místnost – dům, kapitola – kniha, větev – strom), zatímco agregace je volná součást nějakého celku, kde části můžou existovat i bez celku a můžou být součástí více různých celků (hráč – tým, žák – škola).
Komunikace (posílání zpráv)
Jde o vztah, kdy jedna strana (odesílatel) předává informace (zprávu) druhé straně (příjemce). Webový prohlížeč odesílá na server požadavek na zobrazení určité webové stránky. Mobil posílá zprávu na nejbližší základnovou stanici, ta zprávu pošle na ústřednu, která zprávu pošle příjemci přes jeho nejbližší základnovou stanici.
Prerekvizita (nezbytný předpoklad)
Prerekvizita označuje nezbytný předpoklad – co musí existovat nebo být splněno před něčím jiným. Vstupenka je prerekvizita pro vstup do divadla, suroviny jsou prerekvizita pro přípravu jídla, znalost čtení je prerekvizitou pro řešení slovních úloh.
Kauzalita (příčina–následek)
Vztah mezi dvěma jevy, kdy jeden (příčina) přímo způsobuje nebo výrazně ovlivňuje druhý (následek). Déšť (příčina) způsobí mokré chodníky (následek). Kouření způsobuje rakovinu. Kliknutí na tlačítko způsobí odevzdání úlohy.
Kauzalita je silnější než pouhá časová následnost (zítřek následuje po dnešku, ale dnešek není příčinou zítřka) i než korelace (spotřeba zmrzliny a počet utonutí spolu korelují, protože obě jsou způsobené teplým počasím). Kauzalita je také odlišná od prerekvizity (trouba je prerekvizita pro pečení, ale přímo pečení nezpůsobí).
Entitně-vztahové modely
Entitně-vztahové modely (diagramy) pomáhají znázorňovat a zpřehledňovat vztahy a vlastnosti mezi objekty. Používají je například databázoví architekti, aby naplánovali, jak bude vypadat jejich databáze. Diagramy jsou ale poměrně jednoduché, takže si s nimi můžeme pohrát i my.
V entitně-vztahovém modelu se vyskytují tři typy prvků:
- Entity představují objekty. Mohou existovat samostatně, nezávisle na ostatních objektech, a mají vlastnosti (atributy). V diagramu se zakreslují do obdélníků.
- Vztahy (relace) propojují entity. Zakreslují se jako diamanty, které jsou spojené čarou s danými entitami.
- Atributy (vlastnosti) patří jednotlivým entitám. Typicky nemají smysl bez entity, které patří – nemohou existovat samostatně. Znázorňují se jako elipsy spojené s danou entitou.
Jednoduchý diagram může vypadat například takto:

Rozebraný příklad: význam diagramu
- Uživatelé sociální sítě mohou zveřejňovat příspěvky a mají určitý počet sledujících.
- Uživatelé a příspěvky jsou entity.
- Jsou propojené vztahem, jehož název říká, jak spolu tyto dvě entity souvisí (uživatel zveřejňuje příspěvek).
- Počet sledujících je atribut uživatele.
Vztahy mohou mít různé četnosti. Četnosti vyjadřují, s kolika entitami může být každá strana v daném vztahu. Uvažme zmíněný příklad sociální sítě. Jeden uživatel může zveřejnit více příspěvků. Ale každý příspěvek je zveřejněn pouze jedním uživatelem. Proto je četnost vztahu „zveřejňuje“ 1 uživatel – více příspěvků. Naproti tomu, pokud bychom mluvili o vztahu „uživateli se líbí příspěvek“, byla by četnost více uživatelů – více příspěvků. To proto, že jednomu uživateli se může líbit více příspěvků, a jeden příspěvek může být „olajkován“ více uživateli.
Kromě entitně-vztahových modelů můžeme vztahy mezi objekty znázorňovat například i pomocí grafů. Pro znázornění postupného běhu programu se naopak používají vývojové diagramy.
NahoruModelování a simulace
Modelování je důležitou součástí mnoha oblastí informatiky (a nejen informatiky). Často jej používáme i bez toho, abychom přímo o modelování mluvili. Například témata Grafy a abstrakce a Abstrakce představují určitou formu modelování.
V tomto tématu se zabýváme především tím, co se označuje jako výpočetní modelování, tj. modely reprezentované na počítači, které následně můžeme strojově simulovat. Pro rozsáhlejší úvod do této oblasti lze použít e-knihu Modelování a simulace komplexních systémů (od jednoho z autorů ).
Zde nabízíme procvičování k základním principům:
- Modely a skutečnost – příklady modelů a zamyšlení nad tím, jakou část skutečnosti modelují
- Použití modelů a simulací – k čemu vlastně modely a simulace využíváme, jaký je účel konkrétních modelů, jak účel simulace ovlivňuje volbu modelu
- Zpětné vazby – cyklické vztahy mezi částmi systému a přemýšlení o nich, důležitý prvek při modelování
- Interpretace simulací – interaktivní práce s konkrétními simulacemi a interpretace toho, co se v nich děje
Modely a skutečnost
Model je zjednodušenou reprezentací skutečnosti. Model se zaměřuje jen na určité části skutečnosti a i ty zjednodušuje. Díky tomu nám ale dobrý model umožňuje o skutečnosti lépe přemýšlet. Takto obecně to vše může znít obecně a neuchopitelně. Ale s modely pracujeme neustále, i když o nich třeba nepřemýšlíme jako o modelech.
Typický příklad je mapa. Mapa je model prostoru. Turistická mapa například zachycuje polohu míst, vzdálenosti, nadmořské výšky. Zachycuje také tvar cest, ale jen zjednodušeně. A mnohé věci ze skutečnosti v mapě vůbec nejsou. Třeba aktuální počasí, barvu budov nebo polohu srn v lese z běžné mapy nevyčteme.
Další příklady modelů:
- glóbus jako model Země,
- modely počasí používané pro předpovídání počasí,
- malá autíčka či vláčky jako modely skutečných aut a vlaků,
- 3D model postavy v počítačovém programu,
- obrázek potravního řetězce jako model vztahů mezi živočichy v přírodě.
Použití modelů a simulací
Model zachycuje pravidla a principy. Pokud model „rozhýbeme“, dostáváme simulaci. Například můžeme simulovat nehodu, ať už pomocí simulace modelu auta v počítači nebo pomocí fyzické nárazové zkoušky (crashtestu). Nebo simulujeme model počasí, abychom předpověděli budoucnost. Ne všechny modely simulujeme. Například u mapy nemá o simulaci příliš smysl mluvit.
Modely a simulace můžeme dělat s mnoha různými účely:
- předpovídání budoucího chování, např. pomocí simulace modelu předpovídáme počasí,
- zkoumání účinnosti opatření, např. pomocí modelu epidemie odhadujeme, jak efektivní může být zavedení karantény,
- porovnání různých možností, např. různých variant křižovatky,
- výuka, trénink dovedností, např. letecké simulátory,
- zkoumání světa, porovnávání hypotéz, např. modely buněk používané v biologii.
Pomocí simulací často zkoumáme otázky typu „Co kdyby?“. Co kdyby rychlostní limit na silnici byl nižší? Co kdyby byla karanténa přísnější? Co kdybychom počítačovou síť propojili jiným způsobem?
NahoruZpětné vazby
Zpětné vazby hrají důležitou roli v práci s modely, ale má smysl o nich mluvit i bez toho, abychom přímo modely vytvářeli. Zpětnovazební cyklus je série příčin a následků, které se vzájemně ovlivňují.
Existují dva základní typy zpětné vazby: negativní a pozitivní. Toto dělení nijak nesouvisí s tím, jestli se nám příslušné děje líbí nebo nelíbí (jde o technické pojmy, nikoliv emotivní hodnocení). Následující obrázek intuitivně ilustruje základní rozdíl mezi negativní a pozitivní zpětnou vazbou.

Negativní zpětná vazba znamená, že změna v jedné složce zpětnovazebního cyklu vede v konečném důsledku ke zmenšení této změny. Negativní zpětná vazba tedy udržuje systém v rovnovážném stavu. Typický příklad je řízení teploty v místnosti pomocí termostatu: pokud je chladno, termostat zapne topení, místnost se ohřeje, topení se vypne. Podobně funguje regulace teploty těla pocením.
Pozitivní zpětná vazba nastává, když změna jedné složce zpětnovazebního cyklu vede v konečném důsledku ke zvětšení této změny. Pozitivní zpětná vazba tedy vyvádí systém z rovnováhy. Příkladem pozitivní zpětné vazby je epidemie infekční nemoci: když přibude nemocných, zvýší se i počet zdravých, kteří s nimi přijdou do kontaktu, a tím se zvýší počet nemocných.
Ve světě kolem nás se vyskytuje mnoho zpětných vazeb, které spolu vzájemně interagují. Porozumět jejich chování není jednoduché. Modelování často využíváme k tomu, abychom zpětným vazbám lépe porozuměli.
NahoruInterpretace simulací
V této sekci si můžete zkusit práci s připravenými modely. Modely vycházejí z nástroje NetLogo, který je obsahuje celou řadu dalších zajímavých modelů.
Modely mají nastavitelné parametry, které ovlivňují chování simulací. Kdykoliv pracujeme se simulacemi, je užitečné zkoumat vliv parametrů na průběh simulace. Cvičení procvičují práci s parametry, porozumění popisu modelu a interpretování výsledků simulace.
Nahoru